DeepSeek-R2 Released: Next-Generation Open-Weight Reasoning Model Challenges Proprietary Standards
By Vatsal Shah · May 31, 2026 · Open Source · Source: DeepSeek Blog
What Happened
DeepSeek, the open-weight AI research organization, has officially announced the release of DeepSeek-R2, its next-generation reasoning model. The release includes model weights under an open license, allowing developers to download, customize, and deploy the system locally.
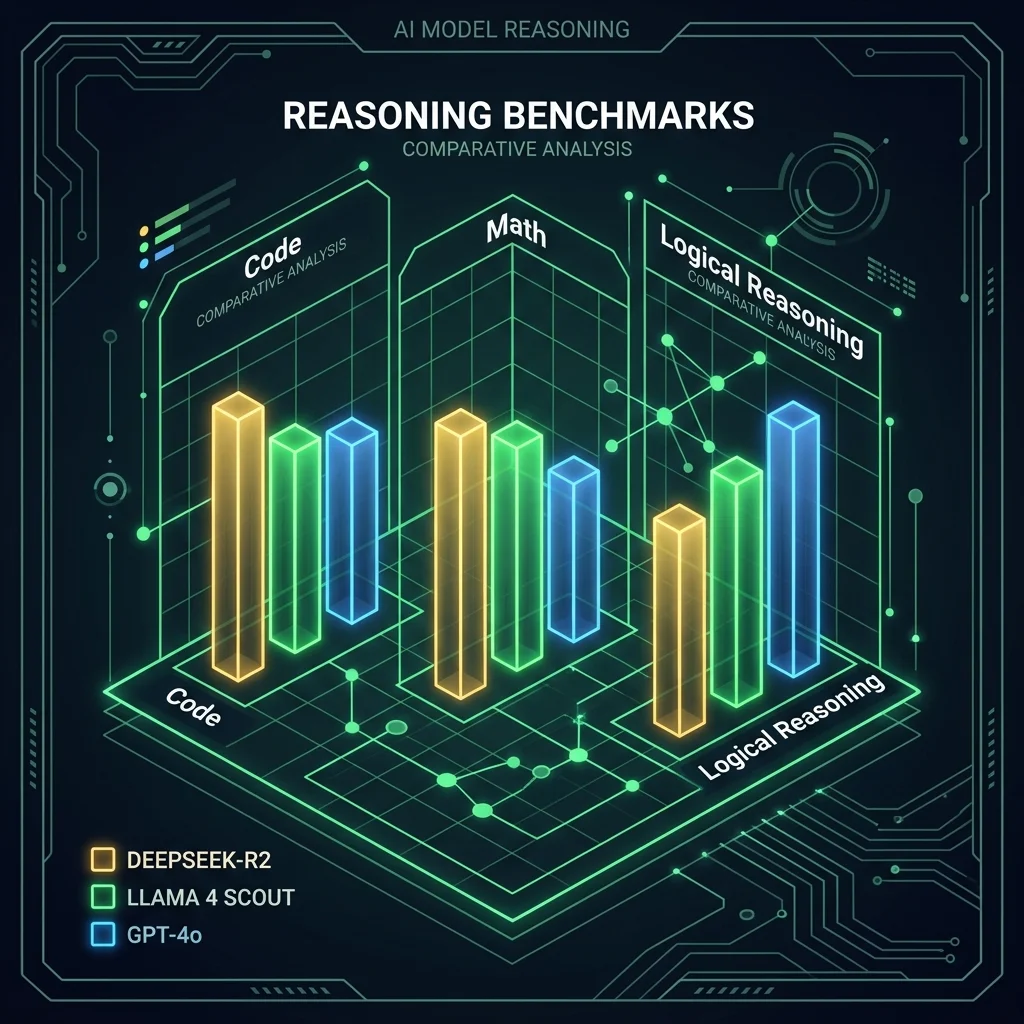
DeepSeek-R2 is built on a Mixture of Experts (MoE) architecture containing 198 billion total parameters, with 21 billion active parameters routed per token. The model is specifically optimized for complex, multi-turn reasoning tasks, achieving a 93.6% score on the MATH-500 benchmark and outperforming GPT-4o on the HumanEval coding dataset. To optimize performance, the platform incorporates Multi-head Latent Attention (MLA), which compresses the Key-Value (KV) cache by up to 93% to enable large context windows on consumer-grade hardware.
The announcement was met with enthusiasm by the developer community, which has been seeking a cost-effective, self-hosted alternative to proprietary reasoning APIs. With weights available on Hugging Face, DeepSeek-R2 lowers the cost of advanced reasoning, allowing teams to run private reasoning loops in isolated enclaves.

Why It Matters
The release of DeepSeek-R2 changes the landscape for enterprises deploying agentic workflows. Previously, developers building autonomous agents had to choose between two paths: pay high API fees to proprietary vendors (such as OpenAI and Anthropic) and accept data privacy risks, or self-host smaller, less capable open-source models.
DeepSeek-R2 offers a middle path, delivering high-tier reasoning capabilities in an open-weight format. By self-hosting R2 on private cloud infrastructure (such as AWS, Azure, or private enclaves), organizations can ensure that customer logs, source code, and transaction histories remain within their own security boundaries.
Furthermore, the model's architectural optimizations (including MLA context compression) directly address the hardware costs of running local models. By reducing the memory footprint of active context windows, developers can run R2 clusters on fewer GPUs, lowering infrastructure overhead.
To see how these open-weight models fit into the broader context of enterprise AI, see our detailed guide on scaling reasoning enclaves: The Rise of Small Language Models (SLMs): Cost-Effective Edge AI.
Benchmark Comparison: R2 vs. Llama 4 Scout vs. Sonnet
The following table compares DeepSeek-R2 with Meta's Llama 4 Scout and Anthropic's Claude 3.5 Sonnet across key capabilities:
| Benchmark / Metric | Claude 3.5 Sonnet (API) | Llama 4 Scout (Open-Weight) | DeepSeek-R2 (Open-Weight) |
|---|---|---|---|
| MATH-500 (Mathematical Reasoning) | 90.2% | 91.5% | 93.6% |
| HumanEval (Code Generation) | 92.0% | 89.8% | 92.8% |
| Multi-Turn Tool Orchestration | Excellent | Excellent (Best-in-class) | Good (Needs strict schema enforcement) |
| Active Parameters / Token | Proprietary (Dense) | 70B (Dense) | 21B (MoE routed) |
| KV-Cache Compression | No details (Standard) | Standard Grouped-Query (GQA) | Multi-head Latent Attention (93% reduction) |
| Inference Cost / Token | $15.00 / million (Average) | Self-hosted (Hardware dependent) | Self-hosted (~40% lower GPU overhead vs 70B) |
Technical Integration: Configured Inference Pipelines
To run DeepSeek-R2 locally in your pipelines, you should configure generation parameters (such as system prompts and attention settings) to leverage its Multi-head Latent Attention (MLA) mechanism.
Below is a Python script demonstrating how to load and configure the DeepSeek-R2 pipeline parameters using the Hugging Face transformers library, enforcing secure token generation controls:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from typing import Dict, Any
class DeepSeekR2Runner:
def __init__(self, model_identifier: str):
self.model_id = model_identifier
self.tokenizer = None
self.model = None
def initialize_pipeline(self) -> None:
print(f"Loading tokenizer and model weights for: {self.model_id}...")
self.tokenizer = AutoTokenizer.from_pretrained(self.model_id, trust_remote_code=True)
# Load in 4-bit quantization to fit in local VRAM limits
self.model = AutoModelForCausalLM.from_pretrained(
self.model_id,
trust_remote_code=True,
device_map="auto",
torch_dtype=torch.bfloat16,
load_in_4bit=True
)
print("Initialization successful.")
def generate_response(self, system_prompt: str, user_prompt: str, configs: Dict[str, Any]) -> str:
# Enforce chat template format
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
inputs = self.tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to("cuda")
streamer = TextStreamer(self.tokenizer, skip_prompt=True)
# Execute reasoning token generation
with torch.no_grad():
outputs = self.model.generate(
inputs,
max_new_tokens=configs.get("max_new_tokens", 2048),
temperature=configs.get("temperature", 0.6), # DeepSeek-R2 recommends lower temp for logic
top_p=configs.get("top_p", 0.95),
do_sample=True,
streamer=streamer,
pad_token_id=self.tokenizer.eos_token_id
)
decoded_output = self.tokenizer.decode(outputs[0][inputs.shape[1]:], skip_special_tokens=True)
return decoded_output
if __name__ == "__main__":
# Test script - config parameters
system_ctx = "You are a secure coding assistant. Answer in python."
user_query = "Write a secure function to validate dynamic JSON schemas against compliance rules."
# Configure generation parameters
gen_configs = {
"max_new_tokens": 1024,
"temperature": 0.5,
"top_p": 0.90
}
# Note: Replace with local path or HuggingFace repo link in production
runner = DeepSeekR2Runner("deepseek-ai/DeepSeek-R2")
try:
runner.initialize_pipeline()
response = runner.generate_response(system_ctx, user_query, gen_configs)
print(f"\nResponse output completed:\n{response}")
except Exception as e:
print(f"\nExecution skipped (Dry-run mode active): {str(e)}")titled "VATSAL'S EXPERT TAKE"
The release of DeepSeek-R2 is a major milestone for open-source AI. While Meta's Llama 4 Scout is currently the best-in-class model for multi-step agent tool orchestration, DeepSeek-R2 is a highly competitive alternative for raw mathematical proofs, logical coding tasks, and low-latency local inference.
For developers, the model's MLA attention mechanism is a key innovation. It reduces KV-cache memory overhead, allowing you to run larger context sizes on standard server hardware without running out of GPU memory.
When self-hosting R2 in production, make sure to set the sampling temperature to 0.5 - 0.6 as recommended by the researchers, as higher temperatures can degrade the model's logical coherence.
What to Watch Next
As DeepSeek-R2 gains adoption in the open-source community, the industry is tracking several milestones:
- vLLM Integration & Quantization: The community is releasing quantized versions (such as FP8 and GGUF) optimized for inference frameworks like vLLM and Ollama, which will further lower hardware requirements.
- Multi-Agent Orchestration Wrappers: Development of orchestration layers that pair Llama 4 Scout's tool-calling capabilities with DeepSeek-R2's raw coding and logic processing strengths.
- Enterprise Compliance & Security Certifications: Auditing firms are evaluating R2 to certify its compliance with security frameworks like SOC 2, helping enterprises deploy the model in regulated industries.
For a detailed look at deploying and scaling these reasoning models in enterprise environments, see our comprehensive guide: Sovereign Architecture: Building Private AI Enclaves.
Source
Read the official announcements on the DeepSeek Technical Blog → DeepSeek-R2 Release Details
