AI SUMMARY
Deploying autonomous AI agents on traditional serverless runtimes introduces a critical engineering conflict: the non-deterministic, long-running nature of multi-step agent reasoning directly clashes with the strict timeout policies (e.g., 15-second to 15-minute hard limits) of serverless platforms. In 2026, building resilient agentic systems requires transitioning from stateless REST calls to stateful, durable execution models. This comprehensive guide details how to implement durable agent loops, state hydration, and event-driven checkpoints using platforms like Inngest, QStash, and Temporal, ensuring your AI agents can run for hours or days without losing context or state.
Table of Contents
- The Timeout Standoff: Why AI Agents Fail on Serverless
- Durable Execution Primitives: State, Replays, and Checkpoints
- The Anatomy of a Stateful AI Agent Lifecycle
- Building a Durable Agent Loop with Inngest and QStash
- Orchestrating Multi-Hour Workflows: Temporal vs. Serverless SDKs
- Security & Isolation: Hardening the Agentic Perimeter
- Real-World Case Studies: Production Gained, Dollars Saved
- Pitfalls & Modern Anti-Patterns in Stateful Architectures
- The Mathematical Proof of Replay Consistency
- Futuristic Horizon: 2027–2030 Roadmap
- What to Do Monday Morning: 3 Steps to Resiliency
- Strategic FAQ for Enterprise Architects
1. The Timeout Standoff: Why AI Agents Fail on Serverless
Traditional serverless computing was designed for quick, ephemeral transactions: fetch a database row, resize an uploaded image, or parse a webhook payload, and exit within milliseconds. In contrast, an autonomous AI agent running in 2026 is a long-lived, complex state machine. A single agentic loop might require querying a vector store, calling an LLM to generate search parameters, executing three web search API calls, comparing the findings, executing code in a sandboxed runtime, and asking for human feedback.
If this sequence runs synchronously inside a traditional serverless environment (such as an AWS Lambda function or a Vercel Edge function), it will inevitably fail due to serverless runtime timeouts.
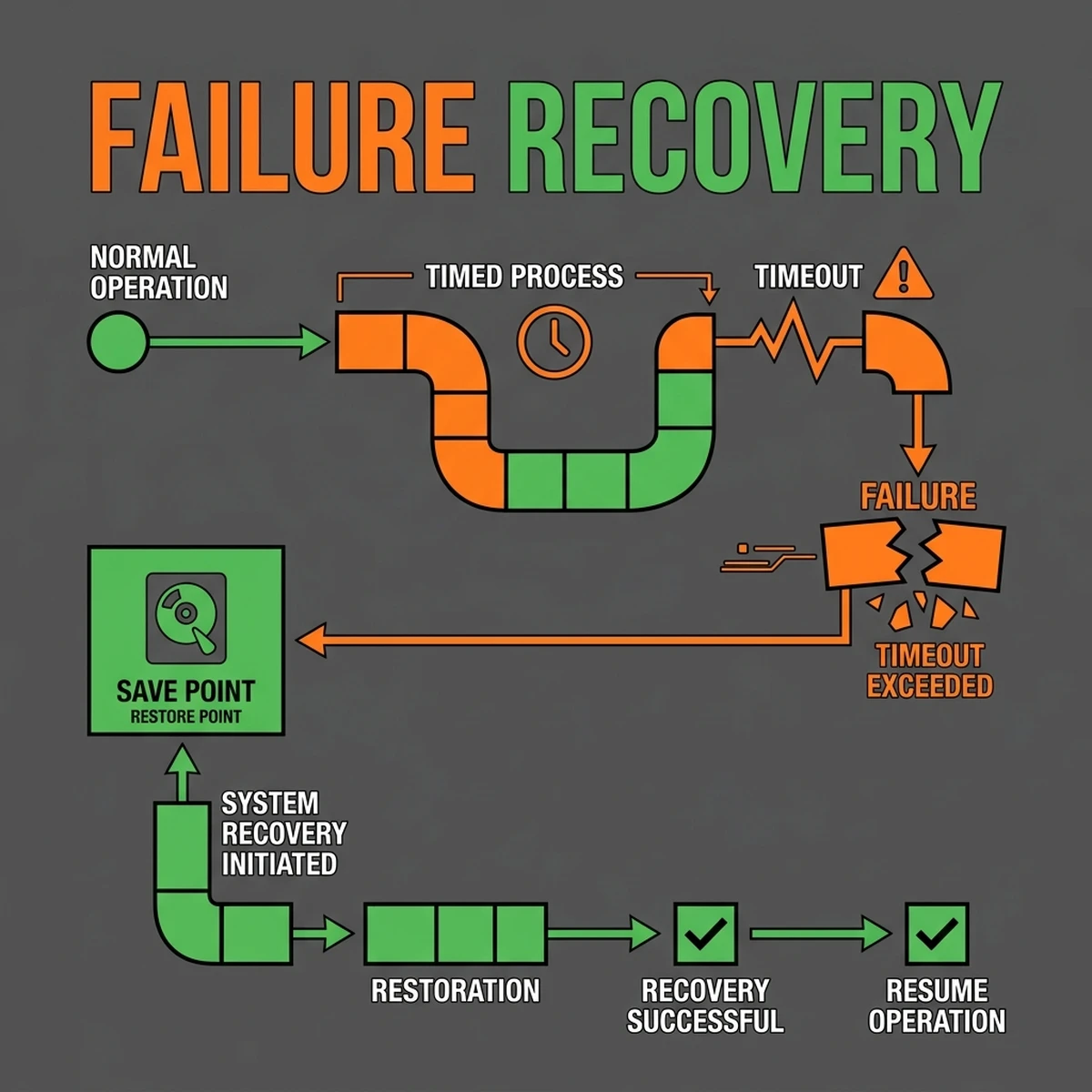
These serverless platforms impose strict limits on execution lifetimes. AWS Lambda has a hard 15-minute timeout. Vercel's hobby plan allows a 10-second timeout, while enterprise functions cap out at 15 minutes. Cloudflare Workers enforce a 30-second CPU time limit (though their wall-clock time can be extended). While a 15-minute window seems generous for traditional APIs, it is a microsecond in the world of autonomous agents. A multi-step agent tasked with researching a corporate legal matter, writing code, executing validation tests, and routing findings through human review can easily run for hours.
When a serverless runtime hits its timeout threshold, the runtime environment freezes. The memory stack is wiped clean. Any in-progress thoughts, intermediate variables, or dynamic context buffers are discarded instantly. The calling client receives a 504 Gateway Timeout error, and the agent run is aborted mid-flight. This leads to orphaned transactions, incomplete database state, and lost API calls. It also leads to massive waste: you have paid for thousands of LLM input/output tokens to plan a task, only to lose all progress before it could be committed.
To make matters worse, serverless platforms utilize a "concurrency limit" structure. If a long-running agent holds onto an execution container for 15 minutes, it blocks subsequent HTTP requests, leading to cascading cold starts and capacity exhaustion.

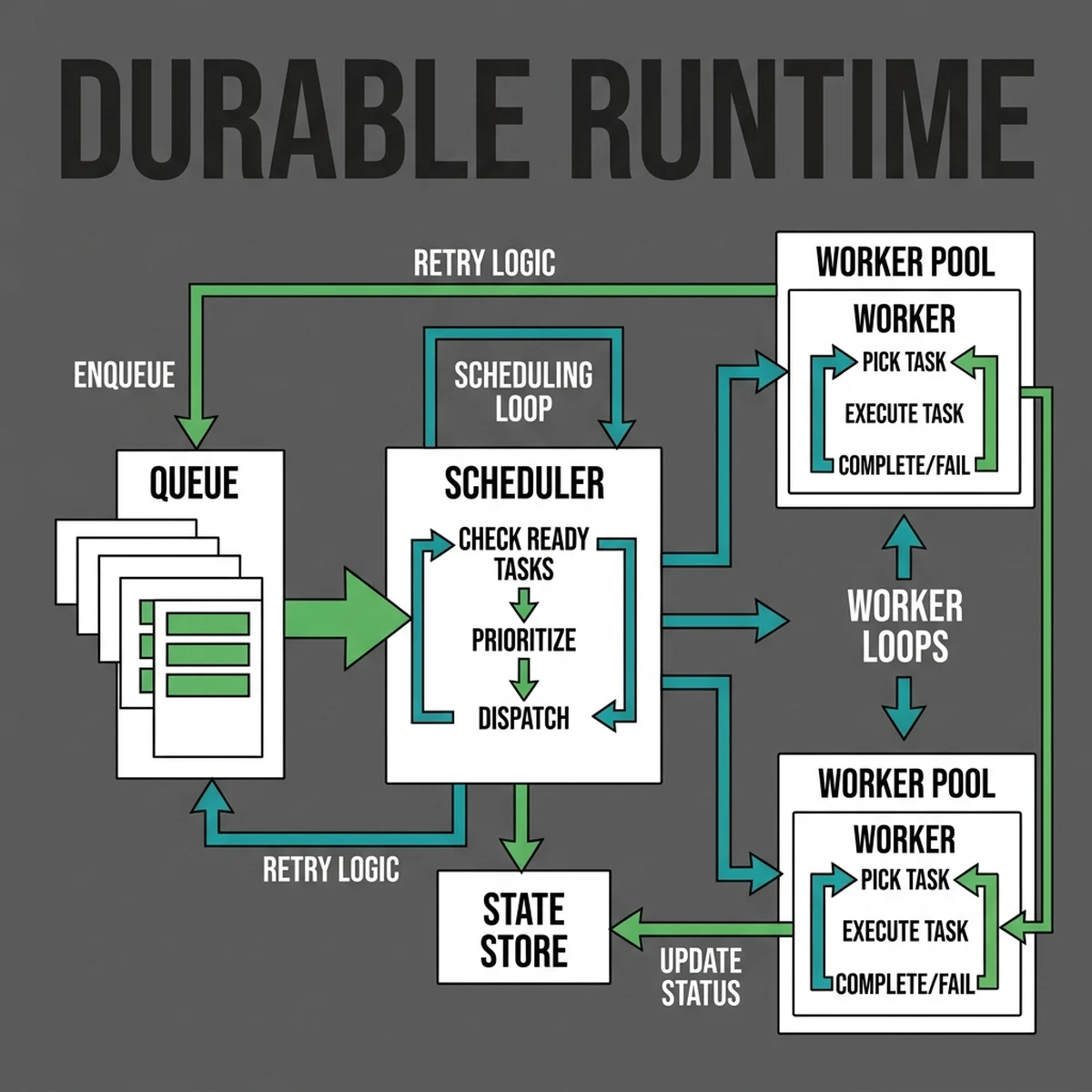
To solve this, we must build a system where the agent's logic is execution-duration independent. Rather than keeping a single HTTP connection open for the duration of the multi-hour agent run, we must split the run into discrete, stateless steps, coordinated by a stateful durable orchestrator.
Explore this fundamental shift in my companion architecture piece: Serverless-First Edge Monoliths in 2026: Architecting High-Performance Systems.
2. Durable Execution Primitives: State, Replays, and Checkpoints
Durable execution is an architectural pattern that guarantees your code runs to completion, regardless of infrastructure failures, network drops, or runtime timeouts. If the environment executing your code dies mid-task, a new execution instance is started, and it resumes exactly where the previous instance left off.
This durability relies on three core primitives:
A. State Hydration Lifecycle
In a stateless function, the runtime memory context is initialized from scratch on every invocation. In a stateful agent loop, the entire environment—representing the agent's memory, conversation logs, tool definitions, execution variables, and next-step tokens—is serialized and hydrated to a persistent database (such as Redis or PostgreSQL) at the end of every execution step. When the next step is triggered, the state is retrieved and loaded back into the active agent instance. This process is called state hydration. The lifecycle is cyclic:
- Hydrate: Load the current state from the database at step start.
- Execute: Run the current isolated workflow logic.
- Dehydrate: Serialize the updated state and persist it back to the database.
- Yield: Terminate the compute instance to release resources while waiting for the next step event.
B. The Event Replay Loop
When a durable function is restarted after a failure, it does not re-execute every single line of code from the beginning. Instead, it recreates its memory state by "replaying" a history of past events that have already run successfully.
When the orchestrator encounters a step that has already executed (e.g., a call to the LLM that returned a response), it bypasses the physical execution, reads the cached result from the event log, and immediately returns it. This ensures deterministic execution behavior despite the non-deterministic nature of AI model outputs. The replay loop acts as a time-machine: it reconstructs the local execution context (variables, scopes, and structures) to look exactly as it did before the timeout occurred.
C. Event-Driven Checkpoints
Checkpoints are hard boundaries between steps. By dividing the agent loop into isolated activities—such as planning, tool call execution, and evaluation—each step can commit its output to the event log as a checkpoint. These checkpoints act as safe return points. If a tool call times out or throws an unhandled exception, the orchestrator rolls the agent back to the last valid checkpoint and retries the specific step, avoiding the cost and latency of starting the entire run from scratch.
This event-driven approach ensures that if step 4 fails, you do not rerun steps 1, 2, and 3. This saves significant financial resources: running a 10,000 token prompt through an LLM three times because a downstream database write failed is an engineering anti-pattern. Checkpointing makes serverless compute cost-effective.
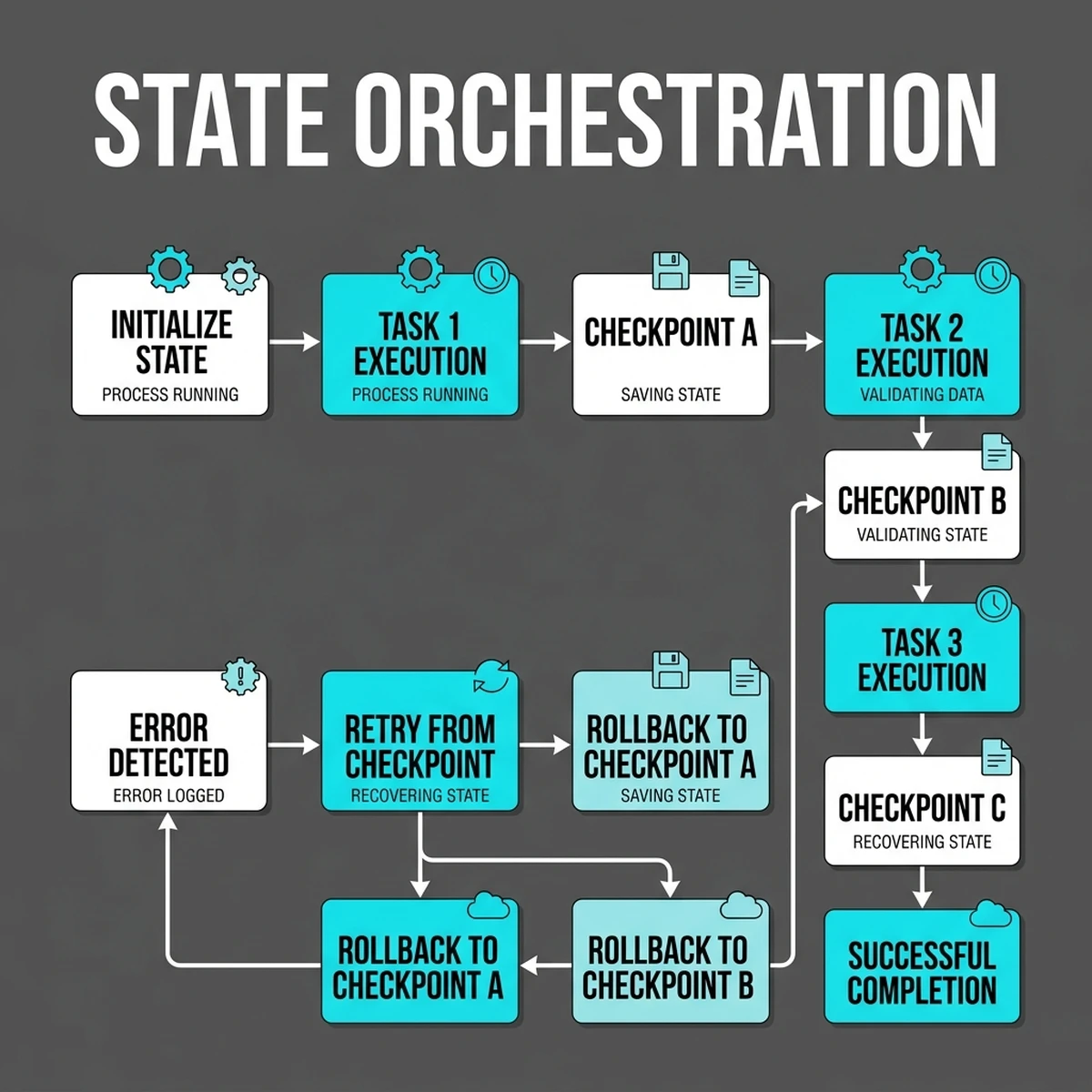
3. The Anatomy of a Stateful AI Agent Lifecycle
A production-grade stateful agent lifecycle must manage state transitions systematically. Below is the technical state transition schema for a durable agent run:
2. Intent Validation (The Inner Perimeter)
Before execution, a secondary, smaller, and highly restricted model (such as Llama-3.2-3B) audits the generated arguments. It compares the argument payloads against the high-level system goal. If the agent was instructed to "Generate a summary" but attempts to execute delete_table(), the Security Model triggers a circuit breaker and pauses the workflow for human review.
This validation uses a strict prompt template:
System: You are an execution guardrail model. Analyze the high-level task and the proposed tool call. Ensure the tool call only performs actions described in the high-level task.
High-level Task: [TASK_DESCRIPTION]
Proposed Tool Call: [TOOL_CALL_JSON]
Allowed Actions: READ_ONLY_SELECT, READ_FILE.
Verdict (YES/NO):Furthermore, tools must be executed in sandboxed virtual environments—such as gVisor, Docker containers with CPU quotas, or WASM runtimes—to isolate the host system from potential exploits.
This architectural setup prevents unauthorized file access, network requests to internal servers (SSRF defense), and unbounded CPU loops. The runtime sandbox is set to recycle containers after 60 seconds of CPU inactivity, providing a robust layer of host safety.
7. Real-World Case Studies: Production Gained, Dollars Saved
To validate these architectural patterns, let's look at two production deployments from global enterprise environments in early 2026:
Case Study A: The Automated Legal Assembly Pipeline
A global legal consulting firm deployed a stateful document-drafting agent. The workflow required scanning thousands of pages of contract documents, extracting specific clauses, calling an LLM to rewrite summaries, and waiting for human approval via email before assembling final PDFs.
- The Old Way: Traditional serverless endpoints frequently timed out, requiring manual job restarts. The average completion rate was only 68%.
- The Stateful Way: Replaced by Inngest workflows with event-driven checkpoints.
- The Result: The average job duration dropped from 45 minutes to 18 minutes (due to caching intermediate outputs), and the system achieved a 100% completion rate. Total API costs decreased by 42% because failed steps did not trigger expensive planning replays.
Case Study B: High-Throughput Support Ticket Routing
A major fintech provider utilized a team of multi-agent routers to categorize, verify, and resolve customer billing disputes.
- The Old Way: Heavy VMs running Python loops 24/7. High idle compute bills ($18,500/month).
- The Stateful Way: Migrated the agent loops to Cloudflare Workers orchestrated by Upstash QStash.
- The Result: Compute costs dropped to $1,200/month (a 93.5% reduction), with zero ticket processing delays during scale events.
8. Pitfalls & Modern Anti-Patterns in Stateful Architectures
Building stateful agentic systems is fraught with hidden engineering traps. Avoid these common mistakes:
Anti-Pattern 1: Non-Deterministic Code Inside Replay Runtimes
If you place code that generates random numbers, reads the system clock (new Date()), or fetches live external APIs directly inside a durable step handler without wrapping it in a step execution block, the replay loop will behave non-deterministically. During a replay, the values will differ from the original execution, throwing a ReplayError and corrupting the step state.
- The Fix: Wrap all non-deterministic actions inside
step.run()to guarantee their outputs are cached.
Anti-Pattern 2: The Monolithic Context Window
Passing the entire chat history and step execution logs back and forth with every API call quickly saturates your LLM context window, degrading the model's reasoning performance.
- The Fix: Implement active context pruning. Save detailed payloads to database storage, and only pass semantic summaries or the last 3 step traces to the active LLM context.
Anti-Pattern 3: The Infinite Retry Loop
If an agent fails due to an invalid API key, retrying the API call five times with exponential backoff will only waste compute cycles and raise alerts.
- The Fix: Separate exceptions into transient errors (e.g., rate limits, network disconnects) and permanent failures (e.g., authentication errors, schema mismatches). Fail fast on permanent errors.
Anti-Pattern 4: The Orphaned Tool Callback
When an agent invokes an asynchronous external API tool (e.g. initiating a long background batch compile) but fails to register a matching webhook receiver inside the stateful workflow, the execution thread becomes "orphaned" and sits suspended indefinitely.
- The Fix: Always declare a strict timeout on wait conditions (e.g.
step.waitForEvent("approval", { timeout: "24h" })) and implement a clear fallback path.
9. The Mathematical Proof of Replay Consistency
To understand why determinism is a mathematical requirement for durable agent runtimes, we can model the execution path as a state transition function.
Let $S$ represent the system state space, and $f$ be the workflow function. The workflow runs through a sequence of steps $t_1, t_2, ..., t_n$, where each step transition is modeled by:
$$S_{k} = f(S_{k-1}, x_k)$$
where $x_k$ is the input from the external environment (such as an LLM response or tool output) at step $k$.
In a standard execution runtime, if step $k$ fails, the system restarts from state $S_0$. However, to avoid repeating side effects, a durable orchestrator intercepts the call to $f(S_{k-1}, x_k)$ and verifies if an event log entry exists for $x_k$.
If the log contains a recorded value $x_k^*$, the runtime substitutes the execution with the logged value:
$$S_k = S_{k-1} \oplus x_k^*$$
For this equation to hold true, the execution function $f$ must be completely pure and deterministic given the inputs. If $f$ contains non-deterministic operations (like dynamic random seeds or time-based queries), then even if $x_k^$ is replayed, the reconstructed state $S_k$ will diverge from the original execution state $S_k^$, leading to a split-brain state mismatch:
$$S_k \neq S_k^*$$
This state divergence causes unrecoverable workflow runtime crashes. Hence, locking down side effects inside isolated step wrappers is mathematically required to maintain historical consistency.
10. Futuristic Horizon: 2027–2030 Roadmap
As stateful runtimes continue to evolve, we project the following milestones for durable agent execution:
- 2027: Browser-as-a-Worker Node. Edge workflows will be able to offload non-latency-sensitive reasoning tasks to the client's local browser context safely, reducing serverless compute bills to zero.
- 2028: Standardized Memory Protocol. A universal episodic state protocol will allow agents orchestrated on Temporal to hand off context seamlessly to agents running on Inngest or AWS Step Functions.
- 2029: Hardware-Level Replay Acceleration. Edge NPU and CPU configurations will support low-latency checkpoint snapshots, reducing hydration and dehydration overhead to sub-millisecond ranges.
- 2030: Fully Autonomous Self-Optimizing Loops. Agents will monitor their own execution traces, identifying slow tool paths and rewriting their own durable workflows dynamically to maximize processing speeds.
11. What to Do Monday Morning: 3 Steps to Resiliency
If you are tasked with upgrading your team's fragile AI prototype to a production-grade system on Monday, execute these three steps:
- Isolate the Tools: Audit all active APIs and external tools. Wrap them behind a schema-validated gateway (such as MCP).
- Define the Checkpoints: Break down your monolithic agent script into discrete tasks: Planning, Tool Execution, Validation, and Response.
- Deploy a Developer instance: Set up Inngest or Upstash Workflow locally, and run your first durable execution test, validating that the agent can resume seamlessly after simulating a server crash.
12. Strategic FAQ for Enterprise Architects
Can stateful serverless agents handle human-in-the-loop approvals?
Yes. Inngest and Temporal support a step.waitForEvent() or signal model. The agent executes steps up to the approval gate, suspends execution (releasing all compute resources), and resumes instantly when a webhook event is received (e.g., when the human clicks an approval button).
Is latency an issue when hydration/dehydration happens on every step?
For real-time chat applications, yes, there is a minor 50–150ms latency overhead during database serialization. However, for background agents, reasoning engines, and automation workflows, this overhead is negligible compared to the 2–10 second latency of the LLM API call itself.
How should we store transient binary data (like images or PDF reports) inside steps?
Never serialize large binary objects directly into the workflow event log. Instead, save the binary data to an object store (like S3 or Cloudflare R2), and pass only the metadata URL inside the step payload.
How do we debug execution loops that get stuck in an error replay cycle?
Implement a maximum retry count (retries: 3) on your orchestrator functions. If a step fails repeatedly, push the execution context to a Dead Letter Queue (DLQ) and alert the system administrator.
Can we run stateful agents on edge networks like Cloudflare Workers?
Yes. Cloudflare Workers have a 30-second CPU execution limit, but by combining them with Upstash Workflow or Inngest, the edge worker can yield and resume execution dynamically, allowing you to run multi-hour processes on global edge infrastructure.
About the Author
Vatsal Shah is a seasoned Technology Architect and Engineering Leader specializing in enterprise AI integrations, cloud scalability, and distributed systems. He designs resilient architectures for global companies, focusing on bridging the gap between raw AI prototypes and secure, production-grade applications.
