AWS WAF Launches AI Traffic Monetization: Publishers Can Now Charge Scraping Bots
By Vatsal Shah · June 25, 2026 · Cloud
The Paradigm Shift: From Gatekeeping to Monetization
For the past several years, content publishers and web platforms have fought a defensive war against autonomous AI scraping bots. As large language models (LLMs) and semantic search tools have proliferated, web scraping traffic has skyrocketed, consuming egress bandwidth and extracting content without referral traffic or direct monetization. In response, web administrators turned to drastic measures—relying on blanket bans in robots.txt, IP range blocking, and aggressive CAPTCHA validation.
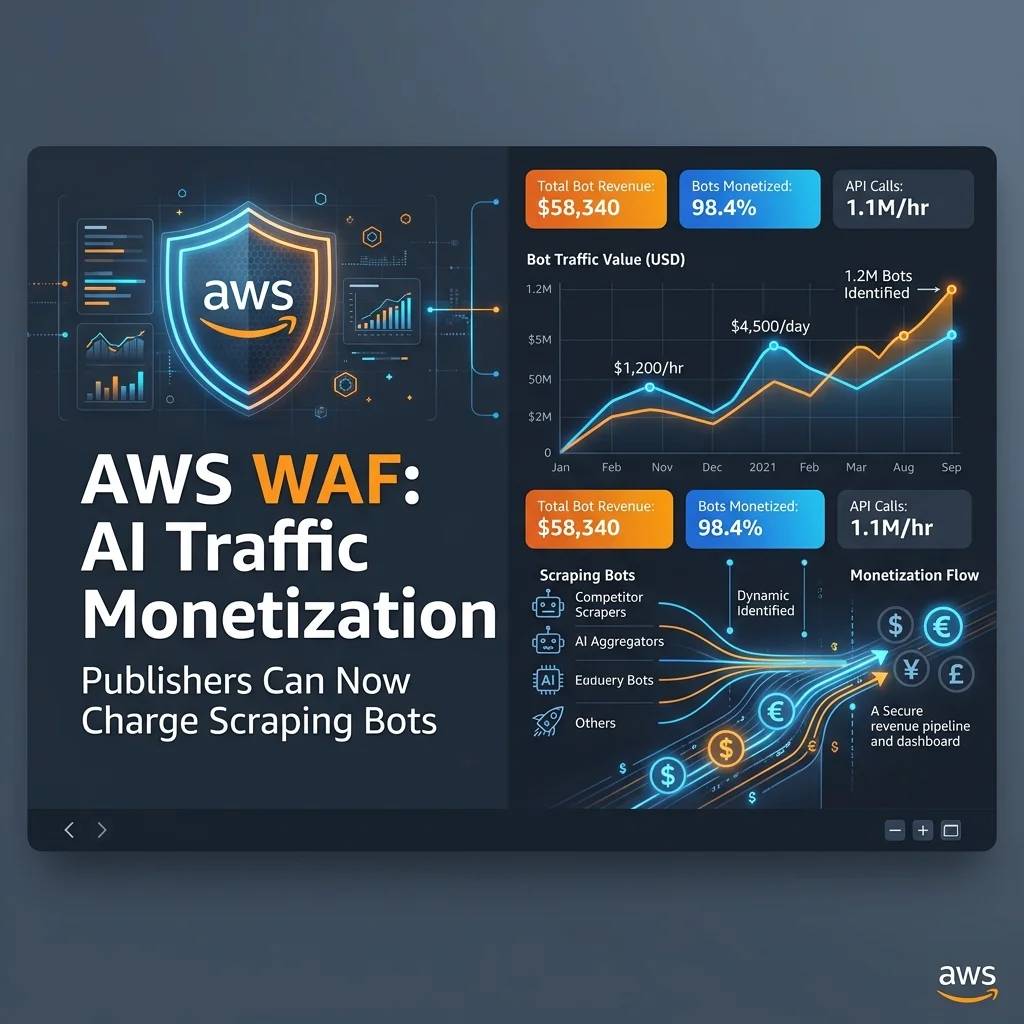
However, blocking traffic ignores a fundamental economic reality: AI developers are willing to pay for clean, structured, real-time training data. Recognizing this, Amazon Web Services announced the launch of AWS WAF AI Traffic Monetization at the AWS Summit NY in June 2026. This service shifts the defensive cyber security landscape by introducing network-level billing for AI scrapers. Rather than block crawling bots at the edge, publishers can now meter, authenticate, and charge AI web crawlers and scraping bots directly at the cloud edge via AWS WAF.
This development alters the content landscape. Instead of forcing publishers to hide behind paywalls—a trend discussed in our analysis of surviving shadow AI and architecting enterprise governance—AWS WAF provides a programmatic path to monetize web scraping activity at scale. It creates a gateway where bot traffic is classified, measured, and charged per request or megabyte, allowing platforms to transform scraping overhead into a predictable revenue stream.
Technical Breakdown: How AWS WAF Bot Metering Works
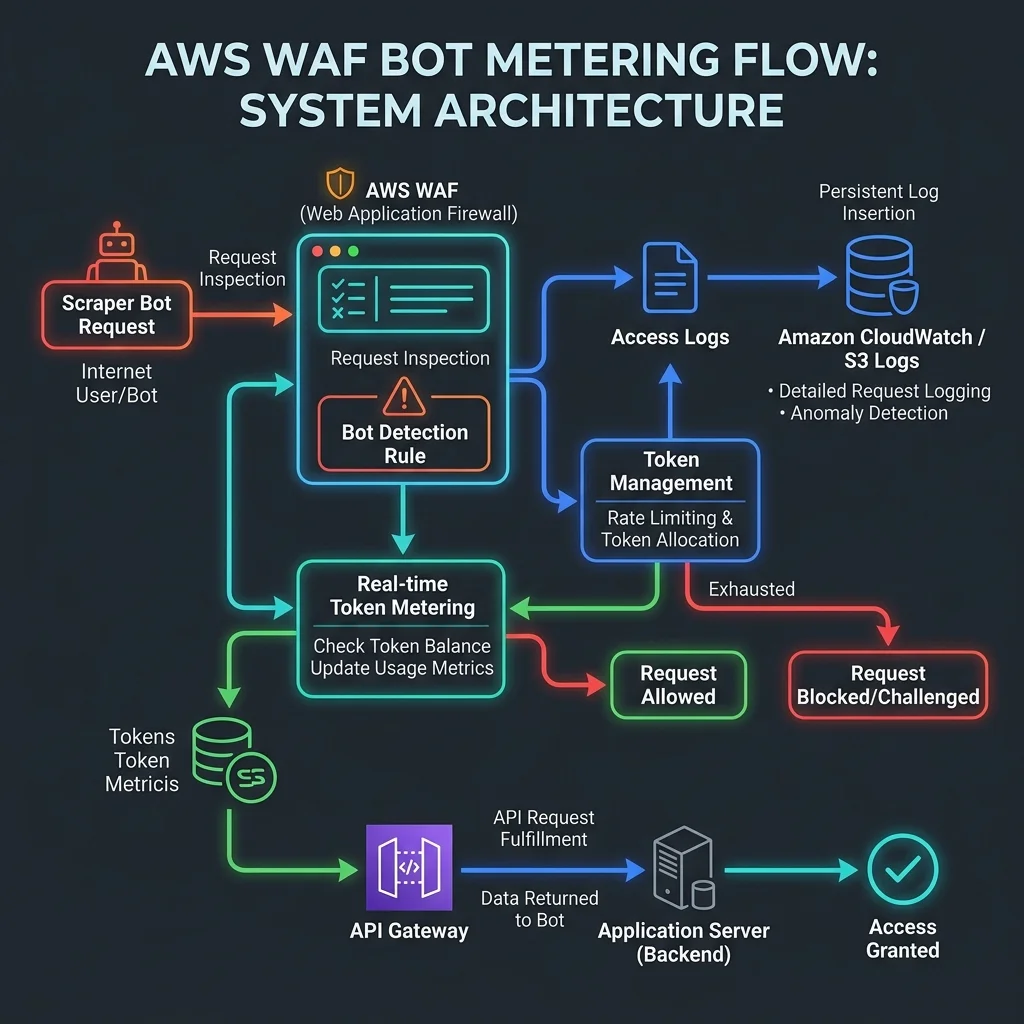
The core of the AWS WAF AI Traffic Monetization engine relies on the integration of AWS WAF web access control lists (Web ACLs), CloudFront edge functions, and Amazon Kinesis Data Streams. When a scraping bot initiates a connection, AWS WAF inspects the request headers, IP address, and TLS fingerprint to determine the bot's identity.
Unlike standard bot control modules that issue a simple block action, the traffic monetization module executes a multi-step verification and metering loop:
- Bot Identification: The request is compared against known AI crawler signatures (such as GPTBot, ClaudeBot, or PerplexityBot) using AWS WAF Managed Rules. Custom rules can also inspect headers for scraping frameworks.
- Token Verification: AWS WAF looks for a standardized authorization header, such as
X-AI-Monetization-Token, containing a cryptographic token linked to the bot developer's account. - Edge Metering: If valid, AWS WAF increments an edge counter. Otherwise, it enforces rate limits, routes to a lower-priority queue, or returns an HTTP
402 Payment Requiredredirect to the developer portal. - Asynchronous Logging: Detailed usage records are streamed via Amazon Kinesis to AWS Billing or external billing engines for ledger reconciliation, minimizing latency on the request path.JSON
{ "ruleGroupName": "AWSManagedRulesAIMonetizationRuleSet", "ruleName": "MeteredScraperAccess", "action": "ALLOW", "meteringMetadata": { "clientId": "client_openai_prod_9928a", "tokenStatus": "VALID", "rateLimitTier": "TIER_A_HIGH_SPEED", "costPerThousandRequests": 0.15, "requestBytes": 14205, "chargeReconciliationId": "rec_7739x8110b" } }
By performing these operations at the CloudFront edge, publishers keep resource-heavy crawling bots off their origin servers. Scrapers pay a fee to access the edge-cached versions of pages, preserving back-end database resources for human visitors.
Technical Comparison: Cloudflare Blocking vs. AWS WAF Monetization
The launch of AWS WAF AI Traffic Monetization contrasts with other edge protection strategies. While Cloudflare's approach (discussed in Cloudflare default AI bot blocking and visibility) blocks all AI bots by default to preserve bandwidth, AWS WAF treats scrapers as commercial clients that should be welcomed if they pay.
| Capability Feature | Cloudflare AI Bot Protection (Default Block) | AWS WAF AI Traffic Monetization (Meter & Charge) |
|---|---|---|
| Primary Philosophy | Threat mitigation and static access prevention | Commercial enablement and programmatic metering |
| Edge Action | HTTP 403 Forbidden, CAPTCHA, or connection reset | HTTP 200 (Metered/Charged) or HTTP 402 (Payment Required) |
| Monetization Support | None (traffic is rejected by default) | Built-in via AWS Billing API, Stripe, and webhooks |
| Crawler Flexibility | Hard block lists requiring manual user exception | Dynamic token limits based on paid developer credit |
| Developer Relations | Pushes scrapers toward proxy networks | Incentivizes scrapers to register and pay for clean access |
| Origin Impact | Zero (blocked at edge) | Zero for cached hits; controlled for metered origin bypass |
By implementing a commercial model, AWS WAF attempts to bridge the gap between AI developers who need vast data inputs and publishers who require sustainable revenue models to support content creation.
Architecture of the Payment Capture Pipeline
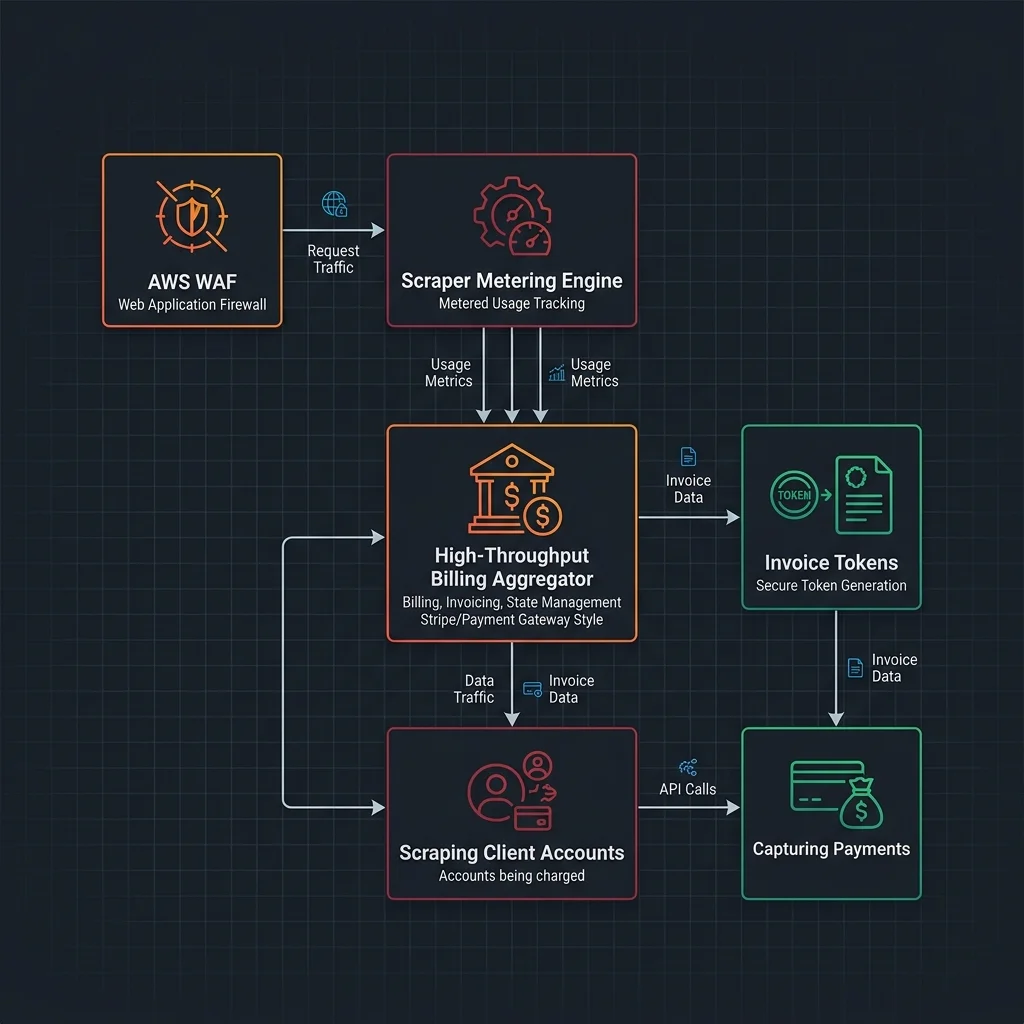
To operate an AI bot charging network, content platforms must bridge edge networking rules with subscription billing engines. This requires a decoupled architecture that processes network actions synchronously at low latency while logging pricing transactions asynchronously.
The reference architecture for an AWS WAF-powered payment capture system utilizes AWS Lambda@Edge functions to validate the incoming scraper tokens against a cache stored in Amazon DynamoDB Global Tables. When the scraping bot sends a request with an authorization token, the Lambda@Edge function verifies the token's validity and current spending limit.
If the token is valid, the request is allowed to pass to the cache or the origin server. Concurrently, a transaction log containing the request size, client ID, and timestamp is pushed to Amazon Kinesis. A downstream worker aggregates these logs and triggers API webhooks on billing platforms like Stripe or customized developer portals. This guarantees that publishers can reconcile micro-transactions and capture payments programmatically based on exact usage.
Incoming Request -> [ AWS WAF / CloudFront Edge ]
|
(Token Check via DynamoDB)
|
+--------+--------+
| |
[ VALID ] [ INVALID / EMPTY ]
| |
(Kinesis Log Stream) (HTTP 402: Link to Portal)
| |
(Billing Webhook) (Block / Rate Limit)
|
[ Stripe / Gateway ]This decoupled approach ensures that billing calculations do not add overhead to the user request path, keeping latency under 10 milliseconds.
The Economic Impact on AI Crawlers and Search Engines
The monetization of scraping traffic will have profound implications for the unit economics of AI developers. Up to now, training models and updating search indices relied on the assumption that web data was free. AI companies could run massive crawl operations, consuming terabytes of content from digital media outlets with no variable content acquisition costs.
If publishers adopt edge-metered pricing systems, the cost structure of running AI search engines will change. Scrapers will have to prioritize their crawl lists, consuming only high-value domains and ignoring lower-quality content. This shift will favor publishers who invest in premium, authoritative content, as they will command the highest CPMs (Cost Per Mille requests) from AI developers. Conversely, it will squeeze smaller AI startups that lack the capital to license web access at scale, potentially consolidating model training power among a few well-funded tech giants.
For publishers, this represents a path back to profitability. Instead of relying solely on declining banner ad revenues and subscription walls, they can license their content directly to machines. The edge WAF acts as an automated tollbooth, ensuring that if a machine consumes content to train a model or answer a user query, the creator is compensated.
Future Considerations: Standardization and Legal Safe Harbors
As network-level bot monetization scales, the industry will require standardization. Currently, there is no single standard for declaring bot-billing headers, meaning AI developers must write custom connectors for different platforms. Organizations like the W3C and the IETF are discussing drafts for web-monetization headers to standardize how payment indicators are passed in HTTP requests.
Furthermore, legal battles around fair use and web scraping continue to evolve. Edge-level billing establishes clear terms of service: by passing a monetization token, AI scrapers enter into a commercial contract. This framework provides legal clarity, giving AI developers explicit permission to train on target data while protecting publishers from unlicensed commercial exploitation. Over the coming years, edge-level billing will likely become the standard compliance gate for web data acquisition.
Frequently Asked Questions
What happens if an AI scraper does not provide a payment token?
If a scraping bot or web crawler attempts to access a protected site without a valid payment token, AWS WAF can be configured to take several actions. The default recommendation is to return an HTTP 402 Payment Required response containing redirect metadata. This guides the scraping client to the publisher's developer portal where they can register, accept the terms of service, and deposit funds to receive an API access token. Alternatively, publishers can block the traffic entirely or enforce rate-limiting to protect server bandwidth.
Can custom bots or small-scale scrapers bypass these rules?
AWS WAF uses advanced heuristics, TLS fingerprinting, and IP reputation data to detect bot traffic, meaning that simple header spoofing is generally insufficient to bypass rules. If custom scraping scripts attempt to masquerade as regular browsers, AWS WAF can trigger JavaScript challenges or CAPTCHAs. While a human visitor can solve these challenges, headless scraping bots cannot, forcing them to either authenticate via the paid monetization endpoint or face rate-limiting and blocking.
How does this affect traditional search engine indexing (like Google Bot)?
Publishers can configure rule exclusions within AWS WAF to allow standard search engine bots (like Googlebot or Bingbot) to crawl free of charge to preserve search index visibility. However, with search engines increasingly utilizing crawl data to power AI summaries rather than directing traffic back to sites, some publishers are choosing to apply metering rules even to major search crawlers, requiring them to compensate for the content used in generative search results.
Sources
- Amazon Web Services: AWS WAF Managed Rules and Bot Control
- AWS Security Blog: Protecting and Monetizing Digital Assets at the Edge
