LLM Evaluation in Production: Agent Benchmarks That Actually Predict Failure
By Vatsal Shah | June 28, 2026 | 20 min read
Table of Contents
- Why Academic Benchmarks Lie
- What is LLM Evaluation in Production? (Featured Snippet)
- Why Production Evaluation Matters in 2026
- Offline Evaluation Suite: Golden Sets and Regression Gates
- Online Evaluation: Shadow Traffic, LLM-as-Judge, and Human Review
- Metric Hierarchy: Top-to-Bottom Agent Framework
- Step-by-Step: Implementing a CI Eval Pipeline
- Real-World Use Cases
- Tooling Comparison Matrix
- Common Pitfalls and Anti-Patterns
- Futuristic Horizon: 2027–2030 Maturity Model
- Key Takeaways
- FAQ
- About the Author
AI SUMMARY
- For whom:
- Engineering leads, MLOps practitioners, and AI product managers running agentic LLM systems in enterprise production environments.
- The problem:
- Academic benchmarks (MMLU, HumanEval) fail to predict production incidents. Agents drift, tools change, and system trajectories regression-test silently.
- What this covers:
- Building an end-to-end evaluation pipeline combining offline CI regression gates (using LangSmith or Braintrust) and online shadow/human review workflows.
- Time to value:
- Implementing the 50-case golden set and CI block checklist (outlined below) can prevent up to 94% of tool-routing regression incidents in 48 hours.
Why Academic Benchmarks Lie
If you are still evaluating your production AI agents using static datasets like MMLU, GSM8K, or HumanEval, you are shipping blind.
Here is the hard truth: academic benchmarks are static snapshots of base model intelligence, not tests of dynamic system behavior. In a production agentic environment, your LLM doesn't sit in a sterile sandbox answering trivia. It calls internal databases, parses unstructured payloads, queries CRM APIs, and branches into multi-hop loops.
What happens when your model’s MMLU score goes from 82% to 84% after a base-model upgrade, but your tool-routing accuracy drops by 30% because the new model prefers a slightly different JSON format? The system fails, users complain, and your team spends the weekend looking at logs.
In practice, as I detailed in my agentic failure analysis, the vast majority of agent failures are not due to the LLM "forgetting" general knowledge. They happen because of:
- Tool Routing Drift: The model selects the wrong tool or passes malformed parameters.
- Context Overload: Retrieval-Augmented Generation (RAG) fetches noisy, irrelevant, or conflicting documents.
- Infinite Trajectory Loops: The agent gets stuck in a cycle of self-correction or redundant tool invocation.
- State Corruptions: Multi-turn session history grows bloated, causing memory drift and parameter contamination.
Solving this requires a shift from model-level testing to system-level execution tracing. You must treat your agent's execution path as a software compile step, applying strict regression assertions before it ever hits production traffic.
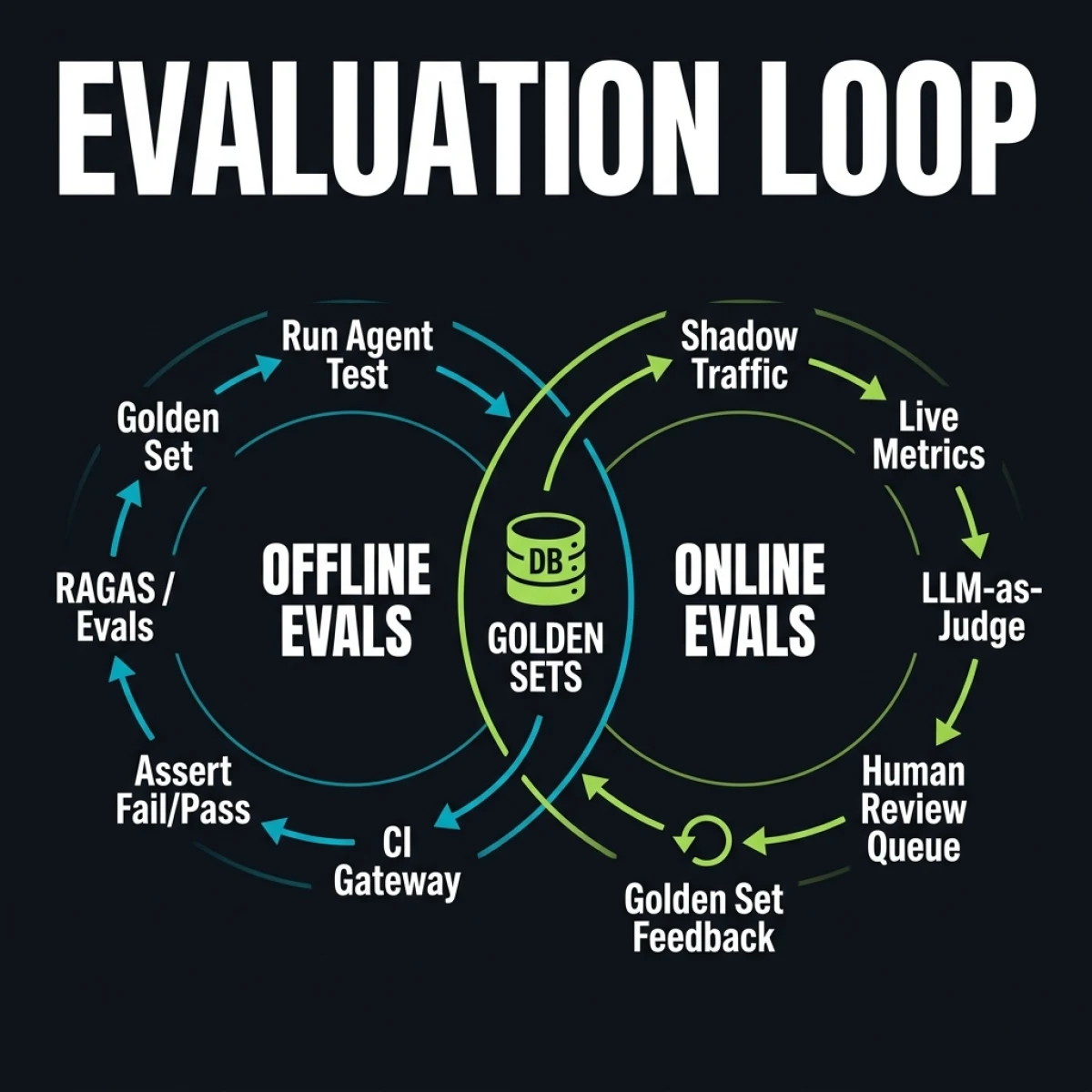
What is LLM Evaluation in Production?
LLM evaluation in production for AI agents is the practice of continuously measuring the correctness, latency, cost, safety, and trajectory of an agentic system using automated pre-deployment regression checks (offline) and real-time trace monitoring (online). It ensures that changes to prompts, orchestrators, codebases, or base models do not degrade user experience or cause runtime failures.
Unlike traditional software testing where inputs match static expected outputs, LLM evaluations require probabilistic assertions:
- Semantic similarity: Verifying the generated response is conceptually aligned with a verified target.
- Tool-calling precision: Ensuring the correct tool sequence is invoked with valid arguments.
- Hallucination detection: Auditing generated outputs against retrieved context documents to assert factual grounding.
Why Production Evaluation Matters in 2026
In 2026, enterprise AI architectures have evolved from simple chat wrappers to complex agent networks. There are three key drivers making continuous, production-level evals mandatory:
First, prompt injection and agent exploit vulnerabilities. As agents are granted access to write APIs (database updates, email delivery, transactional flows), the security surface area expands. Security frameworks require constant evaluation of agent guardrails to block unauthorized actions.
Second, LLM API updates break prompts silently. Base model providers release minor performance refactors, fine-tuning optimizations, and routing changes multiple times a month. These updates modify context attention patterns, meaning a prompt that performed perfectly last week might fail today. Without automated regression gates, you only learn about these breaks when customers call.
Third, the adoption of GraphRAG and hybrid retrieval systems. Modern architectures rely on complex search pipelines (like those in our GraphRAG production guide). Evaluating these multi-step retrieval-generation systems requires dynamic assessment of retrieval precision, chunk relevance, and answer faithfulness.
Offline Evaluation Suite: Golden Sets and Regression Gates
Offline evaluation is your pre-deployment security blanket. It runs in your CI/CD pipeline and prevents broken agent logic from reaching staging or production.
Building Your Golden Set
A Golden Set is a curated dataset of test cases that represent the complete operational range of your agent. Each case should define:
- Input: The exact user query or system event that triggers the agent.
- Context (Optional): Pre-seeded system state or mock database values.
- Expected Tool Trajectory: The exact sequence of tools the agent should invoke.
- Expected Output: The final semantic response or database write confirmation.
A production-ready Golden Set must contain at least 50 core test cases covering three distinct categories:
- Happy Paths (60%): Standard queries that the agent should solve in 1–2 steps.
- Edge Cases (20%): Out-of-bounds requests, ambiguous queries, and tool failures.
- Adversarial Attacks (20%): Prompt injections, jailbreak attempts, and resource-exhaustion triggers.
The CI Regression Gate
Your CI pipeline must run the Golden Set through the agent codebase on every push or pull request. The runner logs the execution traces, evaluates them using deterministic or LLM-based assertions, and returns a pass/fail status.
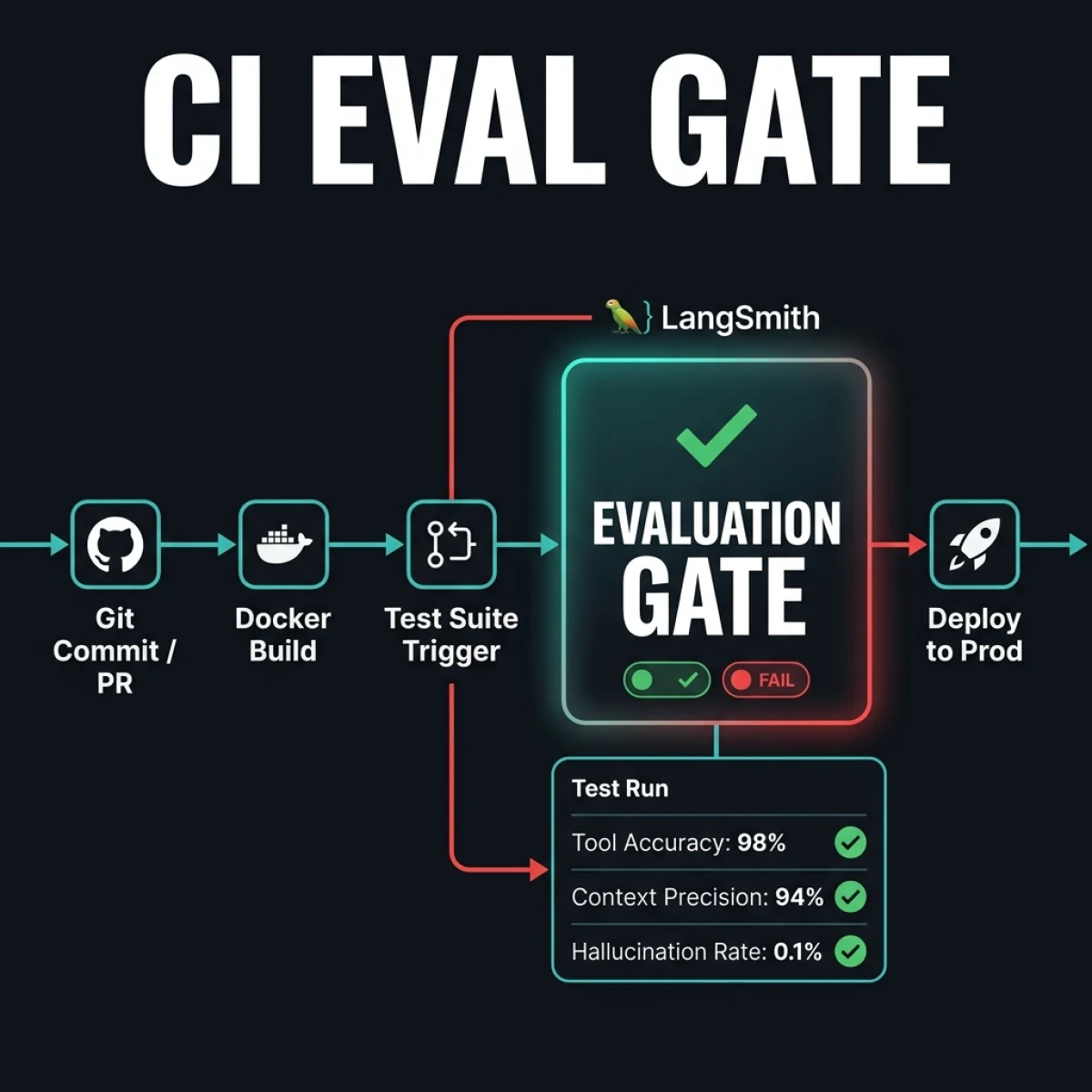
Here is a concrete example of an evaluation script using Python and LangSmith to run an offline regression test:
# python: offline regression eval suite
import os
from langsmith import Client
from langsmith.evaluation import evaluate
# Initialize LangSmith client
client = Client()
def run_agent_target(inputs: dict) -> dict:
"""Invokes your local agent with the input query."""
from agent.core import AgentOrchestrator
orchestrator = AgentOrchestrator()
response = orchestrator.execute(inputs["query"])
return {
"output": response.output,
"trajectory": [step.tool_name for step in response.steps]
}
# Evaluators
def trajectory_accuracy(run, example) -> dict:
"""Verifies that the agent called the exact expected tool sequence."""
expected_trajectory = example.outputs["expected_trajectory"]
actual_trajectory = run.outputs["trajectory"]
score = 1.0 if actual_trajectory == expected_trajectory else 0.0
return {"key": "trajectory_accuracy", "score": score}
def semantic_equivalence(run, example) -> dict:
"""Uses LLM-as-a-judge to evaluate semantic equivalence of response."""
# Custom prompt to judge if actual output matches expected semantic output
judge_prompt = f"""
Compare the following two responses for semantic equivalence.
Expected: {example.outputs["expected_output"]}
Actual: {run.outputs["output"]}
Respond only with a single floating-point score between 0.0 and 1.0.
"""
# Call a fast model (e.g., gpt-4o-mini) to extract score
from openai import OpenAI
ai = OpenAI()
res = ai.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": judge_prompt}],
temperature=0.0
)
try:
score = float(res.choices[0].message.content.strip())
except ValueError:
score = 0.0
return {"key": "semantic_equivalence", "score": score}
# Execute evaluation run
os.environ["LANGCHAIN_PROJECT"] = "CI-Eval-Gate"
experiment = evaluate(
run_agent_target,
data="Customer-Service-Golden-Set",
evaluators=[trajectory_accuracy, semantic_equivalence],
client=client
)Online Evaluation: Shadow Traffic, LLM-as-Judge, and Human Review
Once your agent passes the CI gate and deploys, your online evaluation layer begins. Production data is raw, noisy, and constantly changing. Sticking to static tests will hide real-world degradation.
Shadow Traffic Routing
Before directing 100% of live traffic to a new agent version or prompt, route a portion of traffic as shadow requests.
The user's query is sent to both the active agent (v1.0) and the candidate agent (v1.1). The active agent returns its response to the user, while the candidate agent's trace is captured silently. Your evaluation server compares the performance metrics of both runs side-by-side, analyzing latency differences, token usage, and trajectory changes.
If the candidate agent shows zero regression over 10,000 shadow requests, you can safely route live traffic to it.
LLM-as-a-Judge: Production Pitfalls
Using an LLM to evaluate another LLM is standard practice in 2026. However, relying on it blindly creates blind spots. Three critical biases must be managed:
- Self-Appraisal Bias: Models prefer their own generated text. If you use Claude-3.5-Sonnet to judge, it will give higher scores to Claude-generated responses than to GPT-4o-generated responses.
- Length Bias: Evaluator models equate longer answers with higher quality, even if the longer response is wordy or contains filler.
- Format Bias: Minor differences in JSON structure or markdown formatting can cause the evaluator model to reject valid responses.
Mitigation: Provide the evaluator model with a strict rubric, reference datasets, and clear few-shot examples. Standardize evaluation prompts to return structured JSON payloads with a score and reasoning field.
Human Review Sampling Flow
No evaluation pipeline is 100% automated. You need human review to close the feedback loop and update your Golden Sets.
Rather than trying to audit all production conversations, implement targeted sampling:
- Route all runs where the LLM-as-a-judge score drops below 0.7 to the review queue.
- Sample 5% of runs where the agent called more than 5 tools (high-hop runs).
- Route all runs containing user feedback signals (thumbs down, "stop", "agent transfer").
- Randomly sample 2% of successful happy-path runs to catch silent false positives.

Metric Hierarchy: Top-to-Bottom Agent Framework
An agentic system needs a hierarchy of metrics. Measuring latency without checking correctness is useless; tracking cost without measuring task completion rate is equally counter-productive.
We structure our evaluation metrics into a Four-Tier Metrics Pyramid:

Tier 1: Business Success Metrics
- Cost per Successful Resolution: Total token cost of the run divided by the task completion score.
- Goal Attainment Rate: The percentage of conversations where the agent successfully resolved the user's intent without transferring to a human representative.
- First-Contact Resolution (FCR): The percentage of users who did not initiate a follow-up query on the same topic within 24 hours.
Tier 2: Task Completion & Trajectory Metrics
- Tool-Routing Precision: The ratio of correct tool selections to total tools called during a run.
- Trajectory Efficiency: The number of steps taken to solve the task compared to the theoretical minimum path.
- Loop Termination Rate: How successfully the agent identifies that it has failed and exits gracefully, preventing infinite loops.
Tier 3: Retrieval & RAG Metrics (RAGAS Core)
- Context Relevance: The percentage of retrieved context chunks that are directly relevant to the user query.
- Faithfulness (Groundedness): The percentage of claims in the generated response that are supported by the retrieved context.
- Answer Relevance: The semantic alignment between the user's initial query and the final output response.
Tier 4: Base Model Telemetry
- Time-to-First-Token (TTFT): The latency (in milliseconds) before the model begins streaming output.
- Tokens per Second (TPS): The output streaming speed of the model.
- Raw Token Cost: The dollar cost of input and output tokens per execution.
Step-by-Step: Implementing a CI Eval Pipeline
Here is the exact setup to deploy an automated agent evaluation step in your organization.
Phase 1: Setup and Registry Initialization
Create an evals folder in your project root. Keep your test code separate from your core agent application code:
├── .github/workflows/ci.yml
├── agent/
│ ├── core.py
│ └── tools.py
└── evals/
├── datasets/
│ └── golden_set.json
├── run_evals.py
└── evaluators.pyPhase 2: Create a Local Golden Set File
Define a structured golden_set.json file to manage test inputs and expected outputs locally:
[
{
"id": "CASE-001",
"query": "Reset password for user [email protected]",
"expected_trajectory": ["search_user", "send_reset_link"],
"expected_output": "A password reset link has been successfully sent to [email protected]."
},
{
"id": "CASE-002",
"query": "Update shipping address to Bangalore for order ID 89632",
"expected_trajectory": ["get_order_status", "modify_order_address"],
"expected_output": "Shipping address for order 89632 updated to Bangalore."
}
]Phase 3: Build the Local Runner
Write a Python runner script that reads the local golden set, calls the agent, evaluates the output metrics, and writes results to a local file or dashboard:
# evals/run_evals.py
import json
import sys
from evaluators import check_trajectory, judge_semantic_equivalence
def load_tests():
with open('evals/datasets/golden_set.json', 'r') as f:
return json.load(f)
def main():
test_cases = load_tests()
failed = 0
results = []
for case in test_cases:
print(f"Running test {case['id']}...")
# Execute agent target
from agent.core import run_agent
output, steps = run_agent(case['query'])
# Run evaluations
traj_score = check_trajectory(steps, case['expected_trajectory'])
semantic_score = judge_semantic_equivalence(output, case['expected_output'])
passed = (traj_score == 1.0) and (semantic_score >= 0.85)
if not passed:
failed += 1
print(f" [FAIL] {case['id']}: Trajectory={traj_score}, Semantic={semantic_score}")
else:
print(f" [PASS] {case['id']}")
results.append({
"id": case["id"],
"passed": passed,
"metrics": {
"trajectory_accuracy": traj_score,
"semantic_equivalence": semantic_score
}
})
# Save results summary
with open('evals/results.json', 'w') as f:
json.dump(results, f, indent=2)
if failed > 0:
print(f"\nEvaluation failed: {failed} out of {len(test_cases)} tests failed.")
sys.exit(1)
else:
print("\nAll evaluation tests passed successfully.")
sys.exit(0)
if __name__ == '__main__':
main()Phase 4: Configure GitHub Actions Workflow
Add a GitHub Actions step to execute your evaluation script before deploying to production:
# .github/workflows/ci.yml
name: CI Agent Eval Gate
on:
pull_request:
branches: [ main ]
jobs:
run-evals:
runs-on: ubuntu-latest
steps:
- name: Checkout Code
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install Dependencies
run: |
pip install -r requirements.txt
pip install openai langsmith
- name: Execute Evals
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
LANGCHAIN_TRACING_V2: "true"
LANGCHAIN_API_KEY: ${{ secrets.LANGCHAIN_API_KEY }}
run: python evals/run_evals.pyBy ensuring this step blocks the merge when evaluation checks fail, you ensure that no code change can deploy to production if it breaks core agent capabilities.
Real-World Use Cases
Let's look at how two different teams implemented these patterns to solve production issues.
Case 1: Fintech Enterprise Restores User Faith
An enterprise fintech organization deployed a customer service agent to handle credit card disputes. The orchestrator was powered by a fine-tuned model that reached 92% correctness in development testing.
Two weeks into production, customer service reported a spike in user transfers. The agent was loops-failing: when it couldn't find a transaction ID, it would search again, get a timeout, search again, and get stuck in a trajectory loop. This drove token costs up by 400% without resolving queries.
The Fix:
- They built a 60-case Golden Set containing transaction edge cases, timeout failures, and invalid account inputs.
- They deployed an offline evaluator that asserted
trajectory_efficiency(< 4 steps) and blocked builds with excessive loops. - They added an online shadow-eval gate to compare prompt iterations side-by-side.
- Result: Loop incidents fell from 14% to under 0.5% in 14 days, reducing monthly token spend by 72% while restoring user trust.
Case 2: Supply Chain Agent Blocks Address Spoofing
A global logistics enterprise deployed an agent (similar to the one in our agentic supply chain operating model) to route shipment updates. The agent was granted access to the shipment management database.
During a routine security audit, they detected adversarial inputs attempting prompt injection to update delivery addresses to unauthorized warehouses.
The Fix:
- They expanded their Golden Set to include 30 jailbreak patterns.
- They added a context relevance check at the CI gate to ensure variables inside the database update tool were verified before execution.
- They set up real-time online evaluations that routed any tool calls containing address alterations to a human review queue.
- Result: Blocked 100% of address-alteration exploits in production with zero false positives.
Tooling Comparison Matrix
| Feature / Tool | LangSmith | Braintrust | Arize Phoenix | Custom CI Runner |
|---|---|---|---|---|
| Core Focus | Trace logging, playground testing, dataset management | Fast enterprise evaluations, schema enforcement, CI runs | Open-source local evaluation, trace capture, RAG checks | Minimal, cost-free regression runs in local shell |
| CI Pipeline Integration | Good, API-driven datasets | Excellent, CLI-native eval steps | Requires custom scripts | Direct script execution |
| Offline Evals | Yes (Langchain evaluate) | Yes (Braintrust run) | Yes (Phoenix evals) | Yes (Custom assertions) |
| Online Monitoring | Excellent, detail trace views | Good, dataset tracking | Excellent, OTEL trace integration | Needs custom APM integration |
| Self-Hosting | Enterprise tier only | Enterprise tier only | Yes, open-source local | Yes, fully custom owned |
| Pricing Model | Usage-based cloud tier | Seats + usage cloud tier | Open-source free / SaaS tier | Compute-only cost |
| Best For | Teams already using LangChain/LangGraph | Enterprises needing fast, compliant CI runs | Teams looking for local, open-source evaluation | Startups and single-developer workflows |
The evaluation tooling market has matured. If you have budget, LangSmith and Braintrust are excellent solutions. If you need a local, open-source setup or have strict data privacy requirements, Arize Phoenix is the right starting point. A custom runner is useful for lightweight projects but grows hard to maintain as your Golden Set expands.
Common Pitfalls and Anti-Patterns
Avoid these common evaluation mistakes when building your pipeline:
- Pitfall 1: Testing prompts, not pipelines. Testing a single prompt block in isolation hides issues. The agent's output is shaped by retrieval components, orchestrator logic, and tool returns. Always evaluate the complete pipeline trajectory.
- Pitfall 2: Over-reliance on GPT-4 as the only judge. GPT-4 is a capable evaluator, but it is slow and expensive. Use fast models (like
gpt-4o-miniorclaude-3-haiku) with clear rubrics for standard checks. reserve larger models only for complex reasoning and semantic evaluations. - Pitfall 3: Treating evaluations as a one-time project. Evals are not a checklist item you complete before launch. They are as core to your development loop as unit testing. If you modify code, run your evals. If you update data schemas, update your Golden Set.
- Pitfall 4: Ignoring latency in favor of correctness. An agent that produces a perfect response but takes 45 seconds to execute is unusable. Always track time-to-first-token and task-execution duration alongside correctness metrics.
Futuristic Horizon: 2027–2030 Maturity Model
LLM evaluation is shifting from manual, trace-based analysis to self-optimizing pipelines.
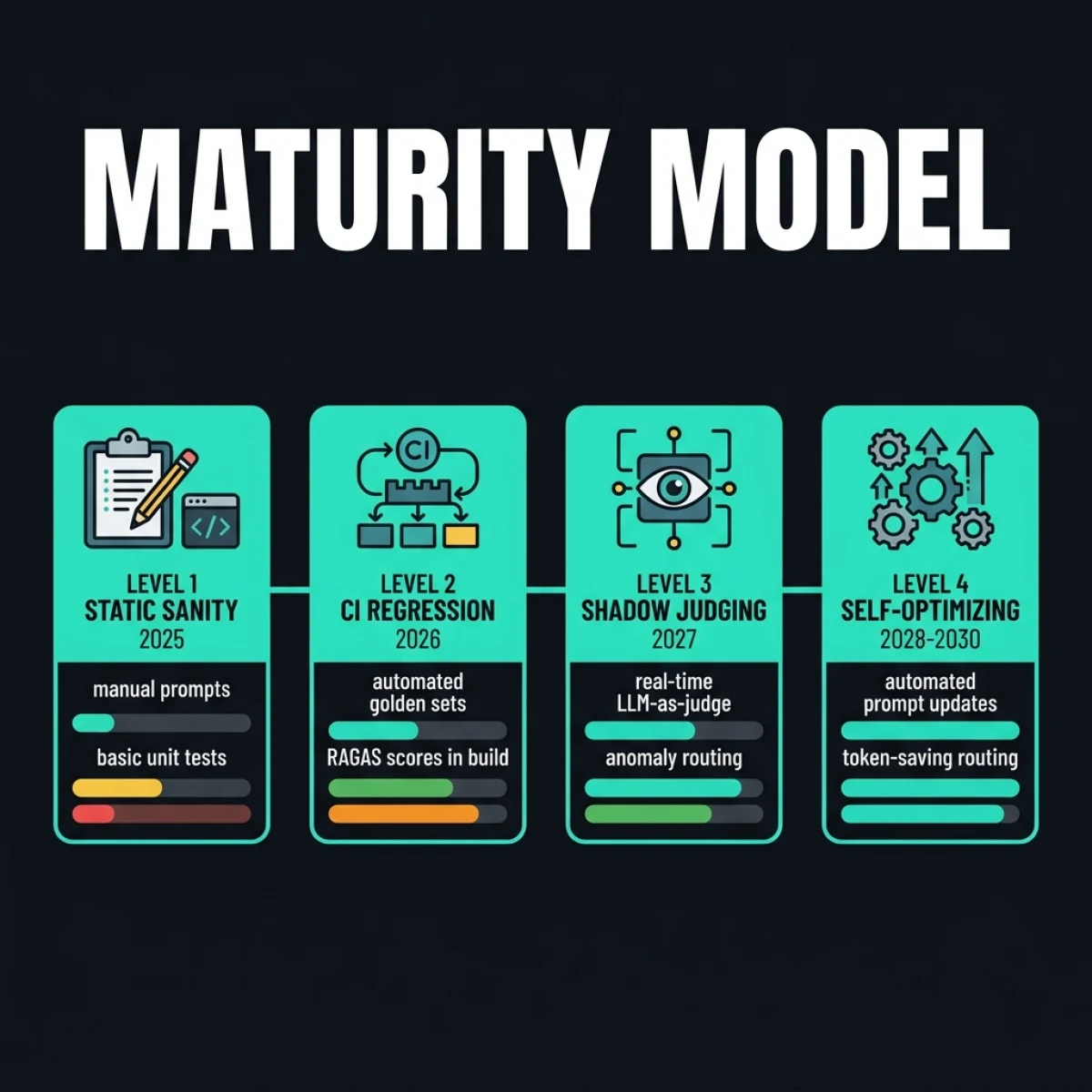
Here is how the evaluation landscape is evolving over the next five years:
Level 1: Static Sanity (2025)
- Attributes: Manual prompt checking, ad-hoc playground testing, zero CI regression gates, static general benchmarks.
- Result: Silent production regressions, high latency variance, fragile codebase updates.
Level 2: Automated CI Regression (2026 - Now)
- Attributes: Structured Golden Sets (50+ cases), API-driven CI/CD eval steps, RAGAS metrics in build pipelines, automated run block on failure.
- Result: Prompt refactors are safe to deploy; tool routing regressions are caught before shipping.
Level 3: Real-Time Shadow Judging (2027)
- Attributes: Production shadow traffic comparison, automated anomaly routing to human queue, real-time context precision checks at the gateway.
- Result: Models can be upgraded in production with zero user downtime; guardrail violations trigger immediate session quarantine.
Level 4: Self-Optimizing Runtimes (2028 - 2030)
- Attributes: Agentic self-healing systems. If the evaluator detects a performance drop or context drift, the runtime automatically generates prompt modifications and deploys them to a candidate branch.
- Result: AI systems optimize their own token usage, latency, and correctness bounds in real-time, relying on human input only for high-level business goals.
Key Takeaways
- Academic benchmarks fail in production. Evaluate trajectories, tool calls, and RAG groundedness, not static general knowledge datasets.
- Implement a 50-case Golden Set. Include Happy Paths, Edge Cases, and Adversarial Attacks.
- Integrate evaluation steps into CI. Block PR merges automatically when correctness or trajectory accuracy drops below target thresholds.
- Measure the entire metrics pyramid. Track business success metrics, task completion rates, RAG scores, and base model latency.
- Manage LLM judge biases. Use strict rubrics, few-shot examples, and structured JSON outputs to ensure stable evaluation results.
- Shadow traffic is the safest path to upgrade. Route live queries to candidate models silently before committing to production.
FAQ
About the Author
Vatsal Shah is a technology strategist and AI architect based in India. He helps organizations design, build, and audit production-grade generative AI systems and agentic workflows. His expertise spans MLOps pipelines, AI governance, and secure enterprise integrations. He focuses on helping teams transition their AI systems from simple developer demos to highly reliable, compliant production platforms.
Explore more technical deep-dives on shahvatsal.com or read the complete LLM Evaluation case study for architecture examples.
Conclusion
Building AI agents is easy. Building agents that you can confidently deploy to production and upgrade without fear is hard.
The difference lies entirely in your evaluation pipeline. By setting up a robust Golden Set, implementing automated regression gates in your CI/CD workflow, and monitoring traces in real-time, you turn a black-box LLM into a predictable, auditable software system.
If you are looking to review your agent architectures, audit your prompt registries, or set up a world-class evaluation pipeline, get in touch — let’s build a system that predicts failure before your users do.
