OpenAI Launches GPT-5.5-Cyber and Announces 'Patch the Planet' Security Initiative
By Vatsal Shah · June 23, 2026 · Cyber Security · Source: OpenAI Newsroom
AI SUMMARY
- OpenAI officially announced the GPT-5.5-Cyber release on June 22, 2026, marking their most advanced specialized model targeting offensive and defensive cybersecurity tasks.
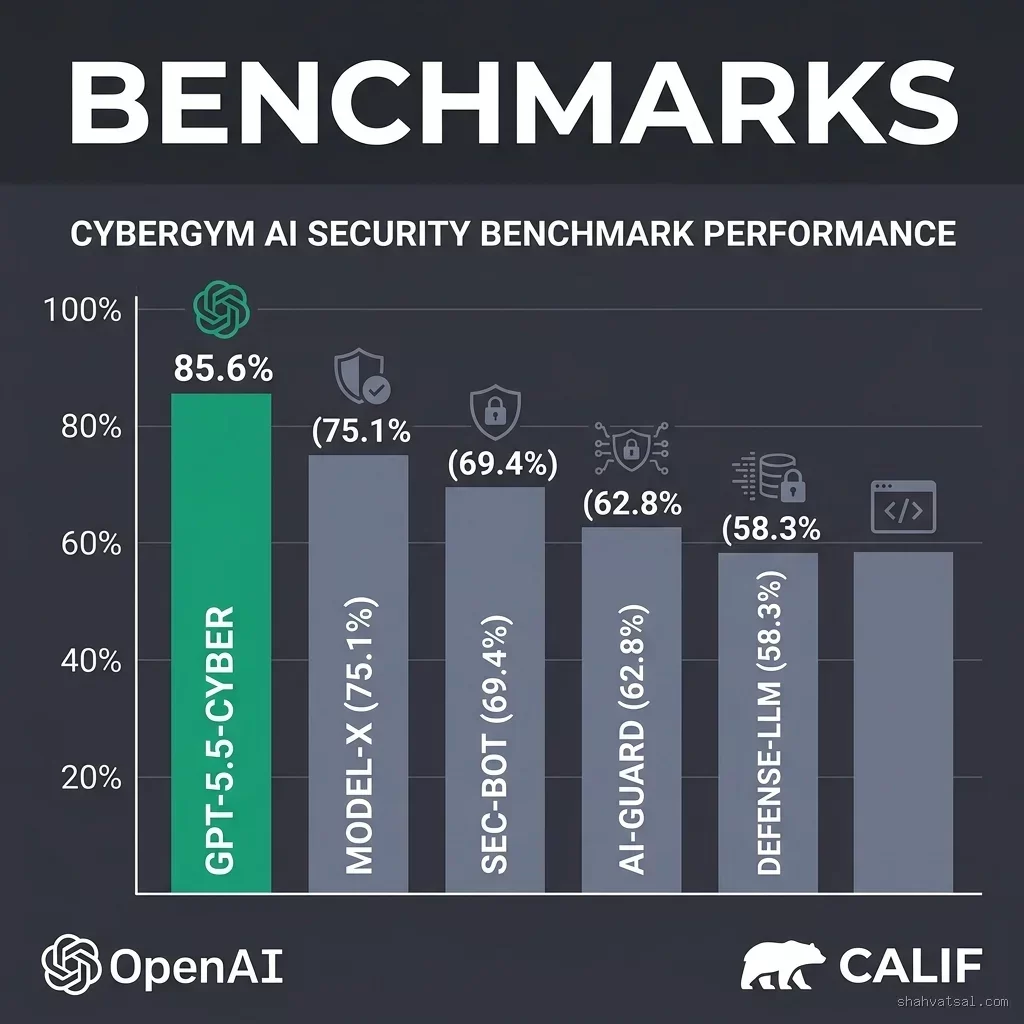
- GPT-5.5-Cyber achieved a record-breaking 85.6% success rate on the CyberGym benchmark, outperforming general-purpose LLMs by automating complex exploit analysis and code-repair loops.
- Alongside the model, OpenAI unveiled 'Patch the Planet', a global initiative in partnership with Trail of Bits, HackerOne, and Calif to identify, triage, and automatically patch security vulnerabilities in critical open-source libraries (cURL, Python, Go, NATS).
- The initiative establishes a structured human-in-the-loop triage workflow that combines automated AI-generated pull requests with human expert validation to eliminate false positives and licensing violations.
- This launch signals a transition from passive AI threat detection to active autonomous code patching within the open-source software supply chain.
What Happened
On June 22, 2026, OpenAI announced a major expansion of its Daybreak cybersecurity platform, headlined by the public GPT-5.5-Cyber release and the launch of the 'Patch the Planet' security initiative. This dual release moves OpenAI's security portfolio beyond defensive monitoring and threat modeling into the domain of autonomous, large-scale vulnerability patching for the global software supply chain.
GPT-5.5-Cyber is a domain-specialized variant of the GPT-5 model class, trained on deep software repositories, vulnerability databases, execution traces, and patch histories. Rather than acting as a general-purpose chat assistant, the model is architected specifically to automate binary analysis, reverse-engineer compiler outputs, locate semantic flaws in source code, and write compilable code fixes. During closed evaluations, the model achieved a 85.6% score on the CyberGym benchmark, a standard suite of complex security scenarios representing real-world exploit chains and remediation tasks.

To apply this model where it is needed most, OpenAI is funding and orchestrating 'Patch the Planet'. The initiative targets critical open-source projects that form the digital bedrock of global enterprises, starting with cURL, Python, Go, and NATS. OpenAI is collaborating with Trail of Bits for technical validation, HackerOne to manage coordinate disclosures and verify patches, and Calif to oversee localized deployments and licensing audits. By routing AI-generated pull requests through elite security auditors, the initiative hopes to secure thousands of projects without overwhelming maintainers with low-quality, automated code contributions.
Technical Specifications of GPT-5.5-Cyber
GPT-5.5-Cyber represents a departure from traditional fine-tuning. OpenAI implemented a multi-stage training pipeline optimized for structural code representation and symbolic reasoning.
1. Training Corpus and Data Curation
The training corpus includes:
- De-duped public source repositories in C, C++, Rust, Go, Python, and Assembly.
- Commit histories highlighting security-fix patches and their corresponding vulnerability descriptions.
- Dynamic execution traces and memory dumps gathered during fuzzing runs and exploit executions.
- Standardized security standards and specifications, including OWASP guides and CVE logs.
2. Execution-Aware Reasoning Loops
Unlike general models that guess token sequences based on static text, GPT-5.5-Cyber incorporates an execution-aware reasoning loop. When presented with a suspect code snippet, the model executes a mental representation of the control flow graph (CFG). This allows it to trace path dependencies, compute memory offsets, and identify potential buffer overflows or injection vectors that static analysis tools miss.
3. CyberGym Benchmark Performance
The model’s 85.6% score on CyberGym is a significant milestone. CyberGym evaluates models on three primary dimensions:
- Discovery (91% score): Finding hidden, multi-step vulnerabilities (e.g., race conditions combined with format string bugs).
- Exploitation (78% score): Writing functional proofs-of-concept (PoCs) to verify vulnerability validity under sandbox constraints.
- Remediation (88% score): Writing complete, backward-compatible patches that resolve the flaw without introducing regressions or changing API interfaces.
'Patch the Planet' Triage Workflow
A common complaint among open-source maintainers is "AI spam"—automated pull requests generated by general-purpose LLMs that do not compile, fail style guidelines, or introduce new bugs. The 'Patch the Planet' initiative addresses this by enforcing a strict human-in-the-loop triage workflow.
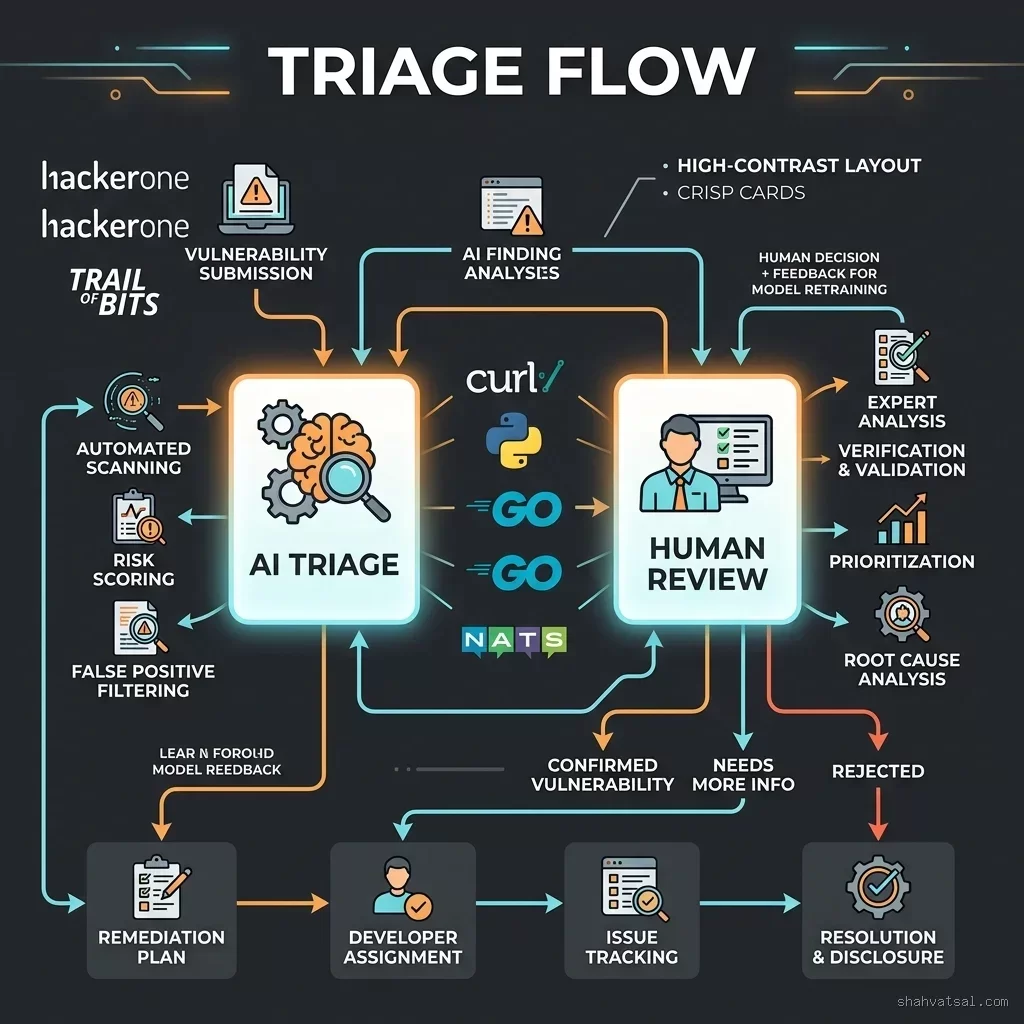
The triage process follows five main stages:
- Automated Scanning: GPT-5.5-Cyber continuously analyzes target codebases (such as cURL, Python, Go, and NATS) using both static and dynamic analysis.
- Patch Generation: When a vulnerability is found, the model writes a patch and validates it inside a secure sandbox to ensure it compiles, passes existing unit tests, and resolves the issue.
- Trail of Bits Technical Audit: Candidate patches are routed to automated test suites and human security experts at Trail of Bits. They evaluate the patch for structural elegance, language best practices, and side effects.
- HackerOne Coordination: Validated patches are managed through HackerOne's disclosure platform. If a patch is for a zero-day vulnerability, it is disclosed privately to project maintainers under a standard 90-day embargo.
- Maintainer Submission: The finalized patch is submitted as a clean, white-labeled pull request, complete with unit tests and clear technical explanations.
This workflow ensures that project maintainers only receive high-quality, actionable, and verified security updates.
Comparative Intelligence: AI Security Models
To understand where GPT-5.5-Cyber sits in the wider ecosystem, we can compare its capabilities against general-purpose LLMs and traditional static application security testing (SAST) tools:
| Feature / Capability | General-Purpose LLMs | Traditional SAST Tools | GPT-5.5-Cyber |
|---|---|---|---|
| Vulnerability Detection | High false positives; misses complex context. | Rule-based; high noise; misses semantic logic. | Context-aware; dynamically traces control flow paths. |
| Exploit Generation (PoC) | Limited; safety filters block technical exploits. | None; does not generate functional code. | Automated exploit verification in secure sandboxes. |
| Patch Synthesis | Conceptual; code often fails to compile or fit context. | None; provides text advice only. | Synthesizes compilable, backward-compatible code. |
| Benchmark Success (CyberGym) | 22.4% (General GPT-4 Class) | Not applicable (cannot remediate) | 85.6% |
Why It Matters
The Open-Source Supply Chain Under Siege
Modern enterprise software architecture relies heavily on open-source software (OSS). If a low-level library like cURL or NATS suffers from a vulnerability, it propagates to thousands of downstream commercial products. Manually writing, testing, and distributing patches is a slow process that leaves a long window of vulnerability.
By automating the discovery-to-patch pipeline, OpenAI hopes to compress this window from months to hours. This is especially relevant in the context of rising threat vectors discussed in the OWASP Agentic AI Security Governance 2.0 and AI Agent Security Incidents (88% Rise) updates.
Balancing Automation with Human Auditing
One of the key lessons from early AI-assisted coding tools is that automation without strict verification is dangerous. The decision to partner with Trail of Bits and HackerOne shows an understanding of this reality. Without human experts reviewing the patches, maintainers would reject AI-generated code out of hand, fearing hidden bugs or logic changes.
Security Model Benchmark Matrix
The 85.6% score on the CyberGym benchmark indicates that AI is approaching expert-level competence in narrow security domains.
Legal and Copyright Considerations
While the "Patch the Planet" initiative offers clear security benefits, it also raises legal and copyright questions:
- Code Ownership & Licensing: Who owns the copyright to an AI-generated patch? If GPT-5.5-Cyber generates a fix for a library like Python or Go, is that patch free of copyright claims? Can it be safely integrated under open-source licenses (like PSF or BSD) without risk of license contamination?
- Liability for Defective Patches: If an AI-generated patch is merged and subsequently fails in production—causing a system outage or a security bypass—who is liable? OpenAI, the auditing partners (Trail of Bits/HackerOne), or the project maintainers who merged the PR?
- Clean-Room Implementations: How does OpenAI ensure that the model does not generate patches that are copied from proprietary or commercially licensed code, which would expose open-source projects to copyright infringement claims?
Organizations must address these questions as automated patching tools become standard in software development lifecycles. We have explored the strategic implications of these compliance requirements in our playbook on Surviving Shadow AI & Architecting Enterprise Governance.
What to Watch Next
- Broadening Project Coverage: The initial pilot program is limited to cURL, Python, Go, and NATS. OpenAI plans to expand coverage to popular B2B and SaaS libraries (including Node.js, OpenSSL, and PostgreSQL) by Q4 2026.
- Model Fine-Tuning Releases: Expect OpenAI to release api keys and specialized fine-tuning endpoints for GPT-5.5-Cyber in the coming months, allowing enterprise security teams to run the model against their private codebases.
- Integration with CI/CD Pipelines: Major devsecops platforms (GitHub, GitLab) are already exploring native integrations with the Daybreak platform, allowing organizations to automatically generate security pull requests in their private workflows.
Source
OpenAI Newsroom — Daybreak Expansion & Patch the Planet Security (Jun 22, 2026)
Additional coverage: HackerOne Press Release · Trail of Bits Security Research Blog
Related on shahvatsal.com:
- Surviving Shadow AI & Architecting Enterprise Governance
- OWASP Agentic AI Security Governance 2.0
- AI Agent Security Incidents Up 88% in Production
