Why I Built This Framework
Most cloud cost optimization guides focus on CPU utilization, database scaling, or general S3 storage tiers. When teams start deploying Large Language Models (LLMs) at scale, they quickly realize that traditional FinOps principles do not directly map to token-based execution. They either blindly consume pay-as-you-go serverless API endpoints (which become unsustainably expensive at scale) or over-provision massive GPU instances that sit idle for 16 hours a day.
After auditing AI infrastructure across global software platforms and dedicated engineering offices, I built this framework to standardize the decision logic. We need a rigorous, mathematical approach to balance API pricing against dedicated hosting VM overheads. This framework maps your operational readiness, models token pipelines, and provides a clear transition roadmap.
The goal is simple: reduce blended token costs by 40-70% while maintaining semantic output integrity.
When to Use This Framework
You should run this assessment and execute the matching calculator in the following scenarios:
- The Token Cost Cliff: Your monthly API invoices (from Anthropic, OpenAI, or Cohere) are growing exponentially and now represent a significant portion of your cloud operational expenses.
- The Hosting Crossroads: You are deciding whether to upgrade to a frontier API model (like Claude 3.5 Sonnet or GPT-4o) or self-host an open-weights equivalent (such as Llama-3-70B-Instruct or Mistral Large) on reserved or spot instances.
- Structured RAG Scaling: Your application injects long-context prompts (dense PDFs, database schemas, or multi-turn chat history) where prompt caching could yield significant savings but remains unconfigured.
- Multi-Agent Deployments: You are scaling autonomous workflows where agents call other agents recursively, leading to a multiplication of token requests per user session.
The Maturity / Readiness Matrix
Before evaluating raw dollar economics, you must assess your team's capability to deploy and manage LLM infrastructure. The matrix below defines the five core dimensions of LLM FinOps maturity.
| Dimension | Level 1 — Ad Hoc | Level 3 — Managed | Level 5 — Optimized |
|---|---|---|---|
| Hardware & Hosting | Rely entirely on serverless public APIs; no VPC or GPU infrastructure ownership. | Single cloud provider dedicated instances; manual VM staging. | Reserved spot-instance pools; vLLM or TensorRT-LLM containerized orchestration. |
| APIs & Routing | Hardcoded model endpoints inside code blocks; no fallback or routing mechanisms. | Load balancing across two endpoints; manual fallback configuration. | Dynamic routing proxy gateway; classification triaging to match query complexity. |
| Caching & Evals | System prompts sent raw on every request; no context-aware caching. | Basic prefix caching configured; manual cache performance review. | Global caching proxy with dynamic TTL; semantic cache hit evaluation. |
| Output Integrity | Subjective human checks of agent outputs; no automated evaluations. | Basic testing dataset; automated assertion checks in CI/CD pipeline. | Continuous evaluation telemetry; real-time check of semantic similarity. |
| FinOps Lifecycle | Expenditures tracked under general IT cloud bills; no token usage mapping. | Weekly token consumption audits; cost attribution per department. | Real-time telemetry dashboard; cost anomalies trigger auto-alerts and rate limits. |
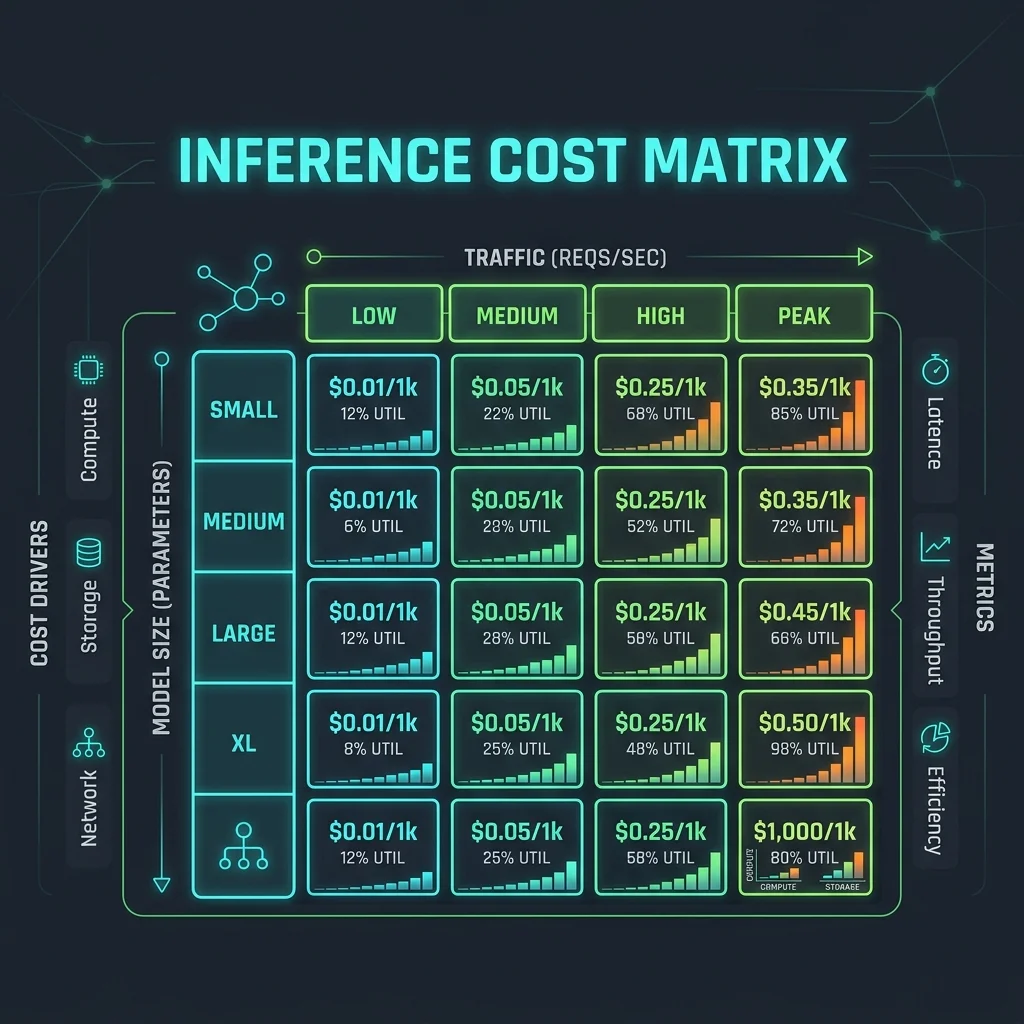
Dimension Scoring Guide
Dimension 1: Hardware & Hosting Amortization
Evaluate how efficiently your infrastructure hosts custom models.
- Level 1 (Score: 1): Public SaaS endpoints only. Developers use personal API keys. No private hosting exists.
- Level 3 (Score: 3): Private VM instances running model servers (e.g. Ollama). GPUs run continuously without autoscaling, leading to high idle compute cost.
- Level 5 (Score: 5): Kubernetes clusters running vLLM or TensorRT-LLM with automatic scaling down to zero. GPUs run in reserved spot pools with automatic replication.
Dimension 2: API Routing & Load Balancing
Rate your pipeline's ability to triage and redirect queries to the most cost-effective model.
- Level 1 (Score: 1): All tasks route to a single premium model (e.g., GPT-4o).
- Level 3 (Score: 3): Basic routing proxy implemented. Trivial categorization (e.g., "short response") maps to a smaller model, but routing is static.
- Level 5 (Score: 5): Dynamic router triages incoming queries based on semantic complexity, user priority, and token budget. Complex tasks use frontier models while simple validation routes to local, self-hosted open-weights models.
Dimension 3: Cache Efficiency & Hit Rates
Measure how effectively your prompts reuse historical tokens.
- Level 1 (Score: 1): Large RAG contexts and system prompts are sent raw on every API request, incurring full pricing.
- Level 3 (Score: 3): Prefixes are structured to allow static prompt caching on supported APIs (e.g., Claude prompt caching), saving up to 50% on input tokens.
- Level 5 (Score: 5): Custom middleware manages a global semantic cache. High-volume system prompts and vector contexts are cached locally, achieving >80% hit rates and reducing input token costs to near-zero.
Dimension 4: Output Integrity & Evals
Assess your capabilities in verifying that cheaper models yield acceptable answers.
- Level 1 (Score: 1): No system for testing output quality. Any model change requires manual debugging.
- Level 3 (Score: 3): Static validation dataset evaluated in CI/CD before staging updates. Checks look for basic structure.
- Level 5 (Score: 5): Continuous evaluation pipelines. Automated LLM-as-a-judge tests verify that routing queries to smaller or self-hosted models does not introduce semantic drift, maintaining parity with frontier models.
Dimension 5: Operational FinOps Lifecycle
Rate how transparent and controllable your LLM expenditures are.
- Level 1 (Score: 1): API bills are reviewed monthly as a single line item. No tracking per user or feature.
- Level 3 (Score: 3): Daily logging of token usage. Cost tracking maps back to specific service modules or business departments.
- Level 5 (Score: 5): Live dashboards displaying token unit economics, real-time cache hit rates, and GPU VM amortization. Anomaly detection scripts flag token loops or runaways and trigger automatic rate limits.
Query Triage and Token Routing Paths
To achieve Level 5 maturity, you must decouple your application code from specific model endpoints. A smart triage proxy acts as a traffic controller, directing queries dynamically.
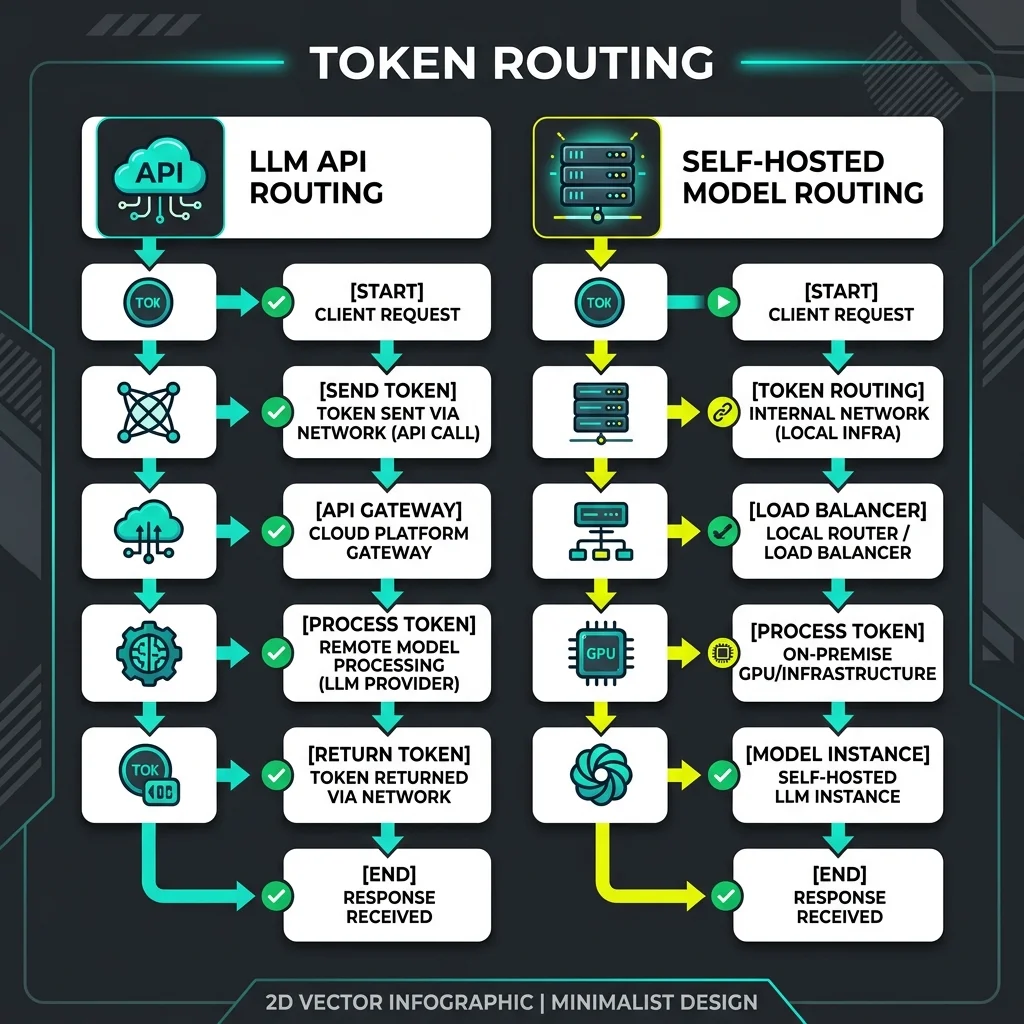
When a user query hits your API gateway:
- Semantic Cache Lookup: The proxy checks if a similar query was processed recently. If yes, it returns the cached result, incurring $0 cost.
- Complexity Triage: A lightweight classifier evaluates the query's complexity.
- Execution Routing:
- If the task is simple (formatting, basic classification), it routes to a self-hosted open-weights model running on spot instances.
- If the task requires deep reasoning or complex context, it routes to a premium frontier API with prompt caching active.
Self-Hosting vs. API Cost Breakdown
Self-hosting open-weights models (like Llama-3) is not free. You must trade off the variable cost of API usage against the fixed, amortized cost of hosting GPUs.
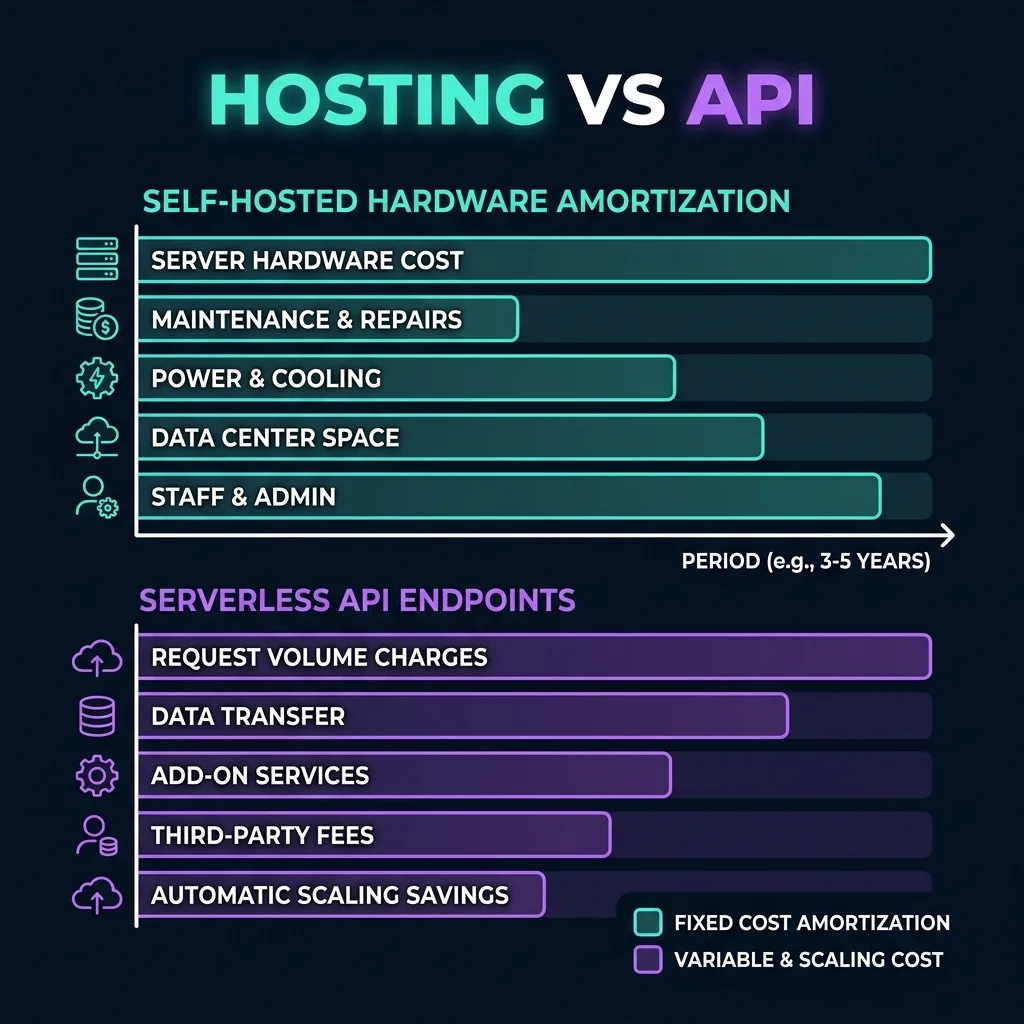
Self-hosting has three main cost vectors:
- Compute Instance Fees: The hourly rate of GPU instances (e.g., A100/H100 VMs).
- Engineering Overhead: The support hours required to configure, secure, and update the model servers.
- Underutilization Penalty: If your VMs run 24/7 but only process traffic during business hours, your real cost per token increases.
Hosted APIs have one primary cost vector:
- Linear Token Consumption: Pay-as-you-go pricing based on input/output token counts.
As shown in Figure 3, self-hosting becomes financially dominant only when token volumes exceed the crossover point—where the fixed compute cost is fully amortized by high, continuous traffic.
Prompt Caching Gateway Logic
Prompt caching is the single most effective way to optimize API expenses without modifying your model selection. It works by retaining prefixes of your prompt in the model server's memory.
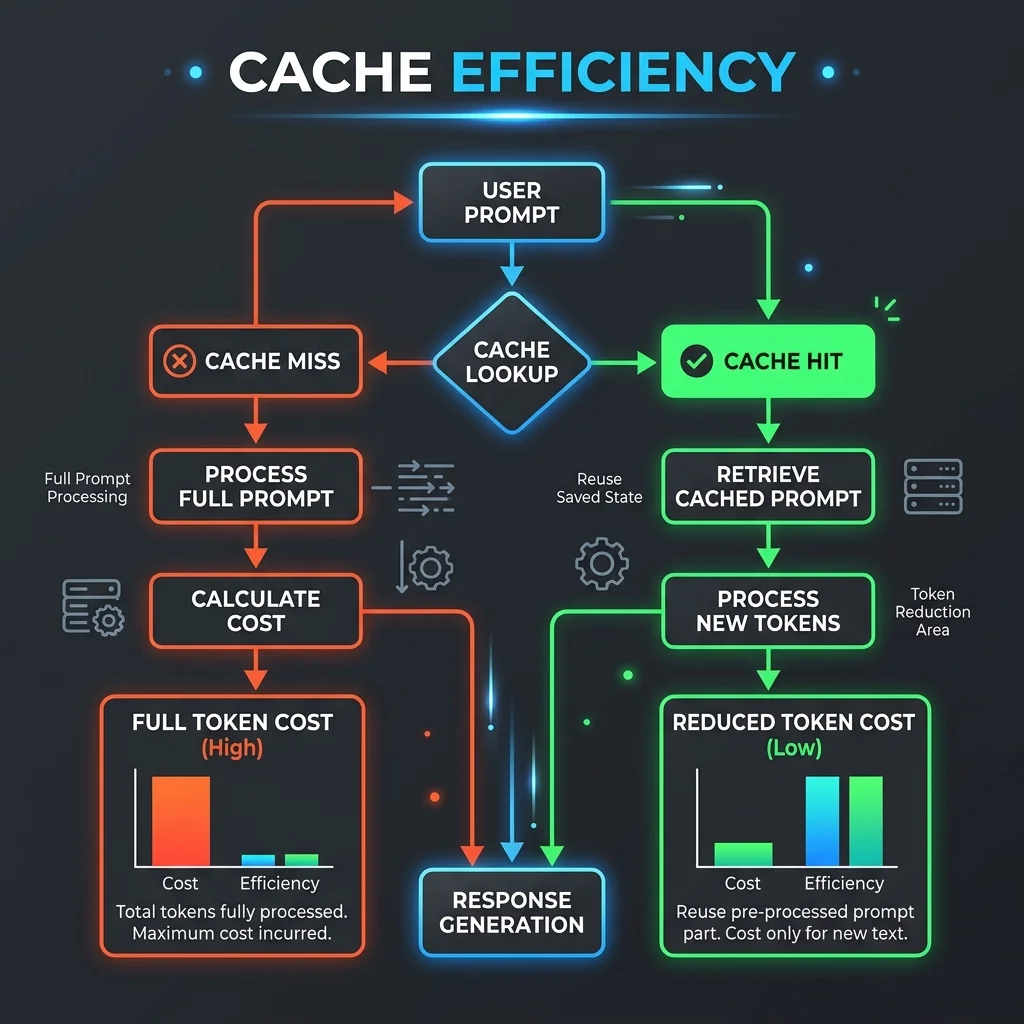
In RAG applications:
- The system prompt, system guidelines, and retrieved documents are structured at the beginning of the request.
- The model server caches this block.
- Subsequent user queries referencing the same document set only charge for the input query tokens and a fractional cache-read fee, saving up to 90% on input costs.
Self-Assessment Checklist
Use these 12 questions to rate your infrastructure. Check each item that is currently operational:
90-Day Action Roadmap
Phase 1: Instrumentation (Days 1-30)
├── Track token usage per user session
└── Enable prompt caching on system prompts
Phase 2: Routing Proxy (Days 31-60)
├── Deploy LiteLLM routing gateway
└── Triage 30% of traffic to smaller models
Phase 3: Hybrid VPC (Days 61-90)
├── Stage self-hosted open-weights models on Spot GPU instances
└── Build dynamic dashboards to report blended ROI to the BoardPhase 1: Days 1-30 (Instrumentation & Quick Wins)
Focus on mapping your current expenditures and activating basic caching features:
- Instrument Token Tracking: Add logs to capture exact input and output token counts per API request.
- Standardize Prompts: Restructure prompts to put system instructions and system guidelines first.
- Activate Provider Caching: Turn on prompt caching features on your API client calls. This yields immediate 30-50% savings on long-context prompts.
Phase 2: Days 31-60 (Query Triage & Proxy Routing)
Introduce software-defined routing gates:
- Deploy API Proxy: Set up a centralized proxy gateway (like LiteLLM) to manage credentials, retries, and fallbacks.
- Implement Simple Classifiers: Write a classifier to route simple queries (e.g., validation checks, text formatting) to cheaper, smaller models (e.g., Llama-8B or GPT-4o-mini).
- Build CI/CD Evals: Create automated evaluation scripts using a small validation dataset to ensure cheaper models maintain target quality.
Phase 3: Days 61-90 (Dedicated Compute & Telemetry)
Amortize high-volume pipelines using open-weights models:
- Provision Spot GPUs: Deploy vLLM or TensorRT-LLM on AWS Spot or Azure Spot instances inside your private VPC.
- Migrate High-Volume Sprints: Route high-volume, standardized processing tasks from hosted APIs to your self-hosted instance.
- Launch FinOps Dashboard: Connect token logs and compute bills to a single dashboard, showing real-time token unit economics and savings.
Common Anti-Patterns
- The One-Model Fallacy: Routing every query to the largest, most expensive model (e.g. Claude 3.5 Opus) because "it handles edge cases better." This indicates a lack of query triage engineering.
- Continuous Idle GPU Nodes: Hosting a dedicated g5.4xlarge instance 24/7 for a feature used only 100 times a day. At low scales, API pay-as-you-go billing is always cheaper.
- Ignoring Prompt Caching TTL: Rebuilding prompt structures dynamically on every API request. This prevents the model server from matching cache prefixes, forcing full price execution.
Downloadable Toolkit
Download these production templates to implement the framework inside your organization. All files are packaged in the project upgrade bundle.
| Deliverable | File Format | Disk Path | Key Purpose |
|---|---|---|---|
| Scoring Workbook | .xlsx | Download Workbook | Excel calculator to compare API and self-hosted GPU node costs. |
| Executive Summary | .pdf | Download Executive Brief | 3-page summary briefing mapping token unit economics for stakeholders. |
| Facilitator Guide | .docx | Download Facilitator Guide | Agenda, prompts, and templates for a 90-minute AI cost assessment workshop. |
| Printable Scorecard | .pdf | Download Scorecard | A print-ready scorecard matrix for scoring internal token pipelines. |
Related Content & Funnel Anchors
This framework is part of our Enterprise AI Transformation Series. To build a complete picture of your organization's AI capability:
- Next Step: Read the Multi-Cloud AI FinOps Unit Economics Blog to see how we track costs across cloud providers.
- Technology Alignment: Read our Serverless Edge Monoliths Blog to learn about light hosting architectures.
- Success Proof: Review the GenAI ROI Recovery Case Study to see this framework in action.
- Need a facilitated assessment? Book an Architecture Review Session.
LLM Inference Cost Assessment Tool
You read the story — now explore the simulated console that mirrors what was delivered. Fictional data only; no production access.
Simulation could not load. Deploy the v1.2.1.0 upgrade package (demo assets under public/assets/demos/) and purge page cache.
Simulation uses fictional data. Controls are for demonstration only and do not connect to production systems.
