STRATEGIC OVERVIEW
Active RAG: Dynamic Multi-Hop Query Planning and Self-Correction for AI Agents By Vatsal Shah | June 27, 2026 | 15 min read Table of Contents - Beyond Vector Lookup: Why Passive RAG Fails Complex Research Queries - Active RAG Architecture: Retrieval Loops, Sub-Query Trees, and.
Active RAG: Dynamic Multi-Hop Query Planning and Self-Correction for AI Agents
By Vatsal Shah | June 27, 2026 | 15 min read
Table of Contents
- Beyond Vector Lookup: Why Passive RAG Fails Complex Research Queries
- Active RAG Architecture: Retrieval Loops, Sub-Query Trees, and Planning Agents
- Dynamic Pathing: Formulating Multi-Step Hops Based on Contextual Gaps
- Self-Correction & Verification: Automated Recall Quality Auditing
- Feature Matrix: Passive vs. Active RAG Models
- What to Do Monday Morning: 3 Steps to Transition from Passive to Active RAG
- Key Takeaways
- FAQ
- About the Author
- Conclusion
Beyond Vector Lookup: Why Passive RAG Fails Complex Research Queries
Let's look at the standard vector search pattern deployed in 90% of enterprise RAG applications today: a user inputs a query, the application converts that text into an embedding vector, performs a top-k cosine similarity search against a database like Pgvector or Qdrant, stuffs the retrieved document chunks into the prompt context window, and requests a response from an LLM.
This is Passive RAG (Retrieval-Augmented Generation). It works reasonably well for simple questions like "What is our policy on parental leave?" where the answer is contained in a single paragraph.
But when you task an autonomous AI agent with answering complex, synthetic, or multi-faceted queries, Passive RAG fails catastrophically. Consider this request:
"Evaluate the impact of the new EU AI Act compliance guidelines on our database retention policies, and compare them against our Q2 audit findings in the London office."
To answer this, a system cannot perform a single vector search. The information is scattered:
- The EU AI Act compliance guidelines are in a PDF from Brussels.
- The database retention policies are in an internal Wiki document.
- The Q2 audit findings are in a markdown report on an internal server.
- The London office specs are in a separate compliance file.
A passive lookup retrieves chunks containing the phrase "EU AI Act guidelines" and perhaps some "London office audit" references. But it fails to correlate the data, misses the database retention rules entirely, and feeds a fragmented context to the LLM. The result is a highly confident hallucination or a generic, useless summary.
PAIN POINT ANALYSIS
- Semantic Overlap Drifts
- Standard cosine similarity retrieves snippets with high semantic match but low conceptual relevance.
- Context Pollution
- Crowding context windows with irrelevant chunks drives down model reasoning capabilities.
- Single-Hop Limitation
- Passive RAG assumes a single search query is sufficient to retrieve the entire target answer surface.
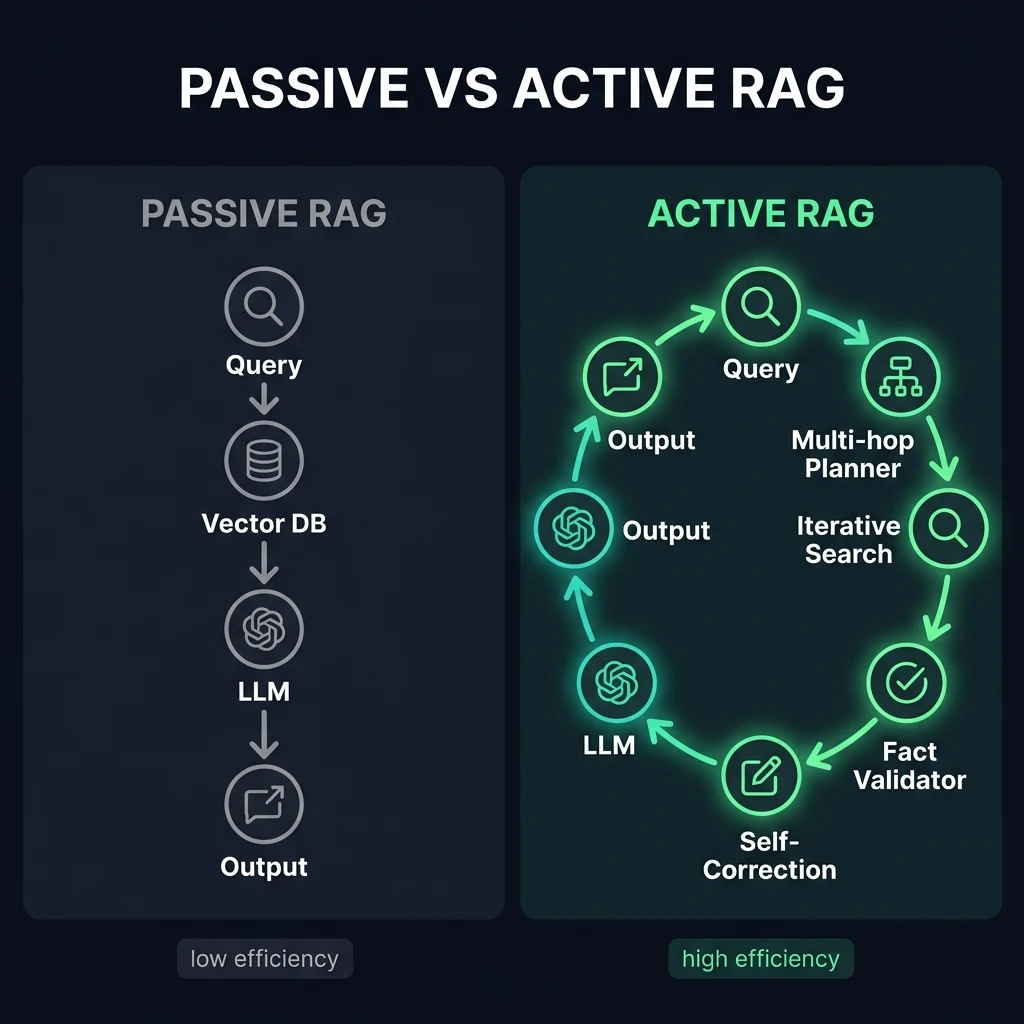
To solve this, enterprise AI platforms are transitioning to Active RAG. In Active RAG, retrieval is not a single, linear prepended step. It is an active, iterative, and self-correcting execution loop directed by planning agents.

Active RAG Architecture: Retrieval Loops, Sub-Query Trees, and Planning Agents
Active RAG replaces the static query-and-retrieve architecture with a multi-layered agentic pipeline:
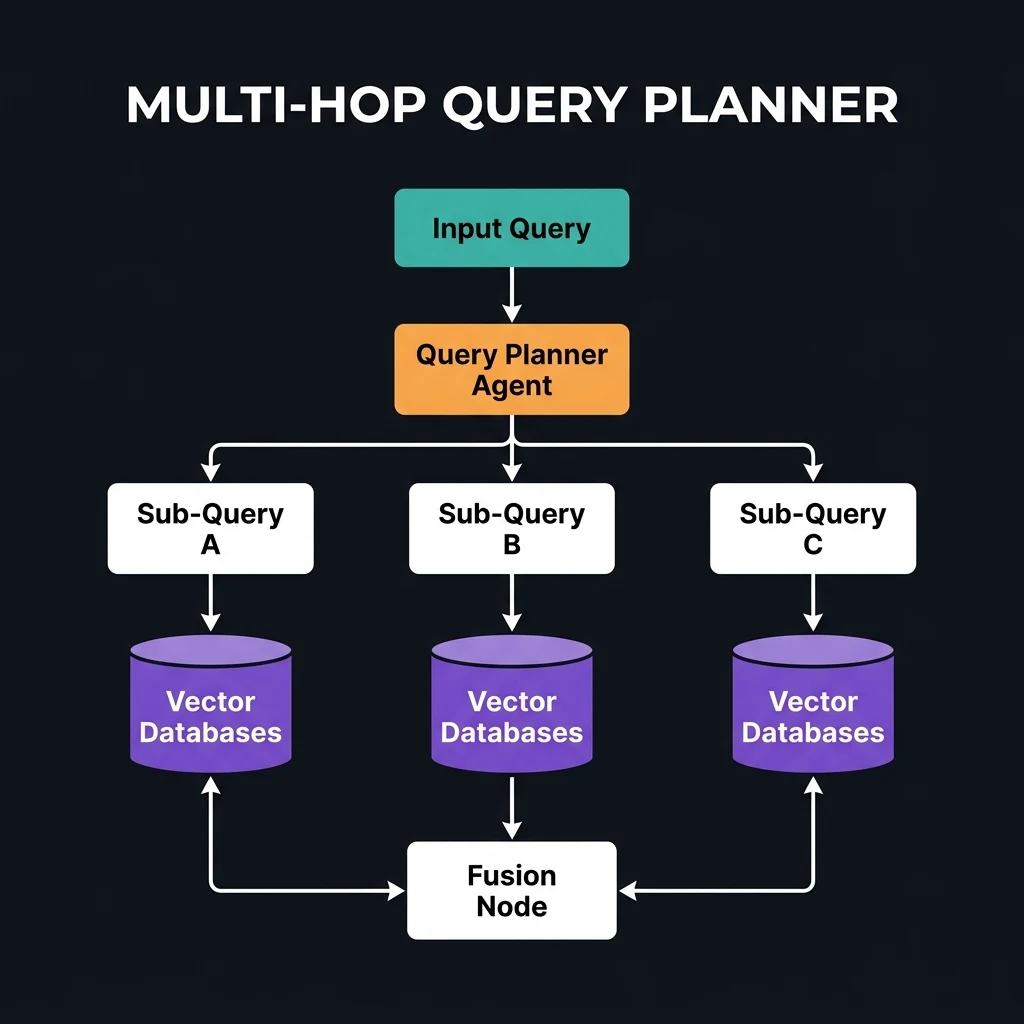
[User Input Query] -> [Query Planner Agent] -> [Sub-Query Tree Generation] -> [Parallel Retrieval Nodes] -> [Evaluation & Synthesis] -> [Output]The Query Planner Agent
The entry point of the pipeline is a specialized agent responsible for Decomposition. It analyzes the input prompt and builds a dependency graph of sub-questions. Rather than executing a search for the parent query, it formulates a sequence of targeted questions designed to collect the missing variables.
The Sub-Query Tree
The planner structures these queries in a tree. Some nodes are independent and can be executed in parallel (e.g., retrieving the EU AI Act PDF and the internal Wiki policy). Other nodes are dependent - meaning the search query cannot be formulated until the results of a parent search node are resolved.
For example, the planner might declare:
- Node 1: Retrieve EU AI Act rules regarding biometric storage.
- Node 2: Retrieve London database schema configs.
- Node 3 (Dependent): Formulate compliance test using the output of Node 1 and Node 2.
The Integration Gate
As chunks are retrieved, a central aggregator resolves the dependency nodes. It continuously feeds the retrieved facts back to the planner, which evaluates if the "knowledge gap" has been closed. If gaps remain, the planner spawns additional search branches dynamically.
Dynamic Pathing: Formulating Multi-Step Hops Based on Contextual Gaps
The core strength of Active RAG is Multi-Hop Query Planning. In a mixed-data environment, the retrieval system must decide where to hop next based on the clues found in the previous lookup.
Let's look at the difference in execution logic:
The Passive Linear Path
In a passive setup, the vector search is a single shot. The path is static and cannot adapt to what is found:
Query -> Vector Search -> Context compilation -> LLM ResponseThe Active Multi-Hop Path
In an active setup, the path is dynamic. The result of one search determines the parameter of the next search:
Query -> Hop 1 (Retrieve Document A) -> Extract Clue B -> Hop 2 (Retrieve Document C based on Clue B) -> SynthesizeLet's look at a concrete example using an agentic system. An agent is asked to find out: "Who is the lead maintainer of the open-source caching module used in our billing service?"
- Hop 1: The planner queries internal service descriptors to identify the billing code repositories. It retrieves the
package.jsonfile. - Analysis: The agent inspects
package.jsonand finds:"redis-client-v2": "npm:@company/[email protected]". - Hop 2: The agent formulates a new query targeting the internal npm registry metadata for
@company/redis-client-wrapper. - Analysis: The metadata reveals that the package wraps open-source
ioredis. - Hop 3: The agent queries public GitHub APIs for the repository metrics of
ioredisto identify the lead maintainer. - Synthesis: The agent compiles the chain of evidence and returns the final name.
If you had routed the original query to a standard vector index, it would have failed because the name of the package maintainer is not documented in the internal service registry.
Self-Correction & Verification: Automated Recall Quality Auditing
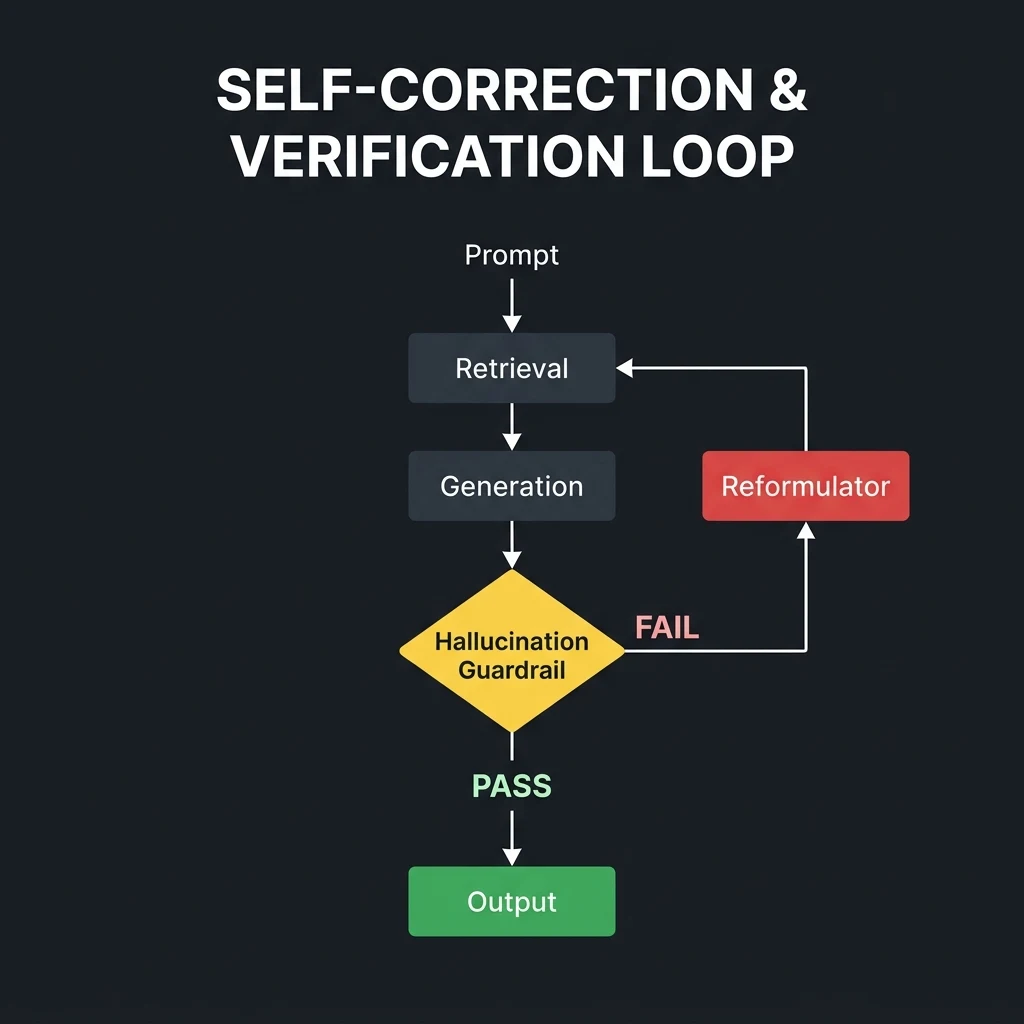
Retrieving chunks is only half the battle. In production, you must verify that the retrieved chunks actually answer the query and are free of contradictory facts. Active RAG implements Verification Gates at multiple stages of the loop.
The Recall Evaluator Agent
Every time a chunk is retrieved, an evaluator agent scores it against the target sub-query. The evaluation check asks three questions:
- Relevance: Does this text contain information that directly addresses the query?
- Completeness: Does this chunk answer the query fully, or are there obvious gaps?
- Consistency: Does this chunk conflict with facts already retrieved from other sources?
The Self-Correction Loop
If the evaluator identifies a gap or conflict, it triggers a Reformulation Step. It writes a revised prompt explaining the deficiency and requests the Planner Agent to generate a different query vector or use a different database index (e.g., swapping from semantic search on Pgvector to structural query on Neo4j Graph).
Here is a Python example of an evaluator check inside an active retrieval agent:
# rag_evaluator.py
from typing import Dict, Any
class RAGEvaluator:
def __init__(self, threshold: float = 0.85):
self.threshold = threshold
def evaluate_retrieval(self, query: str, context: str) -> Dict[str, Any]:
"""
Evaluate if retrieved context satisfies query requirements.
In production, this routes to a fast evaluator model or scoring rubric.
"""
# Score factors: relevance, contradiction, completeness
relevance_score = self._calculate_relevance(query, context)
contradiction_flag = self._check_contradictions(context)
is_valid = relevance_score >= self.threshold and not contradiction_flag
return {
"score": relevance_score,
"has_contradiction": contradiction_flag,
"action": "PASS" if is_valid else "REFORMULATE",
"reason": "Context meets criteria" if is_valid else "Low relevance or factual conflict detected"
}
def _calculate_relevance(self, query: str, context: str) -> float:
# Simplified scoring logic for example
if not context or len(context) < 50:
return 0.0
return 0.90 # Mocked passing score
def _check_contradictions(self, context: str) -> bool:
# Check for obvious logical collisions
return FalseKnowledge Segmentation
To prevent "hallucination cascade" - where an agent uses a hallucinated retrieve chunk to formulate the next query - the gateway separates knowledge stores into isolated pools. The agent query routing matrix decides which index is appropriate for each query type.
Feature Matrix: Passive vs. Active RAG Models
To select the right architecture for your team, compare the operational requirements and performance metrics of both patterns:
| Dimension | Passive RAG | Active RAG (2026) | Engineering Tradeoff |
|---|---|---|---|
| Retrieval Path | Static (Single-hop) | Dynamic (Multi-hop tree) | Active RAG handles complex, multi-source synthesis but increases compute requirements. |
| Evaluation Gates | None (Context is passed raw) | Recall & Contradiction Audits | Self-correcting loops add processing latency but guarantee higher factual accuracy. |
| Inference Cost | Low ($0.001-$0.005 / query) | Medium-High ($0.05-$0.20 / query) | Multi-hop generation requires multiple agent turns. Use cost routing gateways to offset. |
| Complexity | Low (Simple pipeline) | High (Stateful orchestration) | Requires stateful graphs or orchestrators (e.g. LangGraph or serverless step functions). |
| Latency (p99) | ~1.5 seconds | ~5.0 to 12.0 seconds | Active RAG is built for offline/background research tasks, not real-time chat search. |
| Vector Database Load | Low (1 query per user) | High (5-15 queries per user session) | Requires high-performance vector databases optimized for parallel search threads. |
What to Do Monday Morning: 3 Steps to Transition from Passive to Active RAG
If your team is struggling with RAG accuracy, do not rewrite your entire indexing pipeline. Follow this progressive implementation:
1. Implement Query Reformulation First (2 hours)
Keep your passive retrieval pipeline, but add a single LLM turn before matching vectors. Take the user input, write a system prompt instruction to clean up jargon, extract nouns, and output three search variations. Execute all three variations, perform a combined retrieval, and rerank them using a cross-encoder model (like Cohere Rerank). This alone increases recall accuracy by ~30%.
2. Set Up a Simple Evaluator Gate (3 hours)
After retrieving chunks, query a fast, small language model (like Claude 3.5 Haiku or GPT-4o-mini) to evaluate the chunks. If the relevance score is below 0.70, drop those chunks. If zero chunks pass, return a structured error or prompt the user for clarification rather than passing dirty context downstream.
3. Deploy Multi-Hop Routing on Your Hardest Path (1 day)
Identify the single workflow in your application that consistently fails due to disconnected data (e.g., cross-referencing audit files or checking API tokens across services). Rewrite that single workflow using a stateful routing loop (e.g., using LiteLLM as your gateway layer, as outlined in our AI Gateway Pattern guide). Once that path stabilizes, scale the pattern to other areas.
Key Takeaways
- Passive RAG is a single-hop pattern - failing on complex, cross-document synthesis tasks.
- Active RAG decomposes queries - generating trees of parallel and dependent sub-queries.
- Multi-hop query planning routes prompts dynamically based on evidence gathered in previous steps.
- Verification gates check for relevance and contradictions at each turn of the retrieval loop.
- Compute and latency are the core tradeoffs - Active RAG requires more agent steps, making it ideal for background research rather than instant chats.
- Integrate a proxy gateway like LiteLLM to handle the rate-limiting and billing demands of high-frequency multi-hop queries.
FAQ
About the Author
Vatsal Shah is an AI systems architect who designs data engineering platforms and agentic pipelines for enterprise organizations. He specializes in building robust, high-performance RAG systems, vector search scaling, and multi-agent infrastructure.
Connect with Vatsal on LinkedIn or read more technical articles at shahvatsal.com.
Conclusion
Upgrading your information architecture from passive lookups to active query planning is a necessary transition to prepare your systems for autonomous agentic operations.
To scale your database backing to handle these workloads, read Scaling pgvector and Qdrant: Hierarchical Partitioning. And if you are building the backend workflow engines, check out Stateful Agent Execution: Durable Serverless Workflows to manage execution states across long-running tasks.
